VUDDY A Scalable Approach for Vulnerable Code Clone Discovery(S&P 2017)
Abstract#
随着开源世界的扩大,代码克隆的情况也越来越普遍,与此同时,由于代码克隆产生的1day漏洞也越来越多,因此自动化的克隆代码漏洞检测成为一大需求。
本文提出了一种大规模复用漏洞代码检测的方法——VUDDY,能在大规模的代码中精确有效的发现漏洞。
优势:
- 十亿行量级的代码检测只需要14小时17分钟
- 可进行传统的完全检测和部分正规化后的检测
- 规模和准确率完胜其余的相关研究
- 有一定的检测0 day漏洞的能力
Introduction#
代码克隆缺点:
- raise maintenance costs
- reduce quality
- produce potential legal conflicts
- propagate software vulnerabilities
- …
最大的问题在于由于代码克隆,一个已经给出的补丁,并不会马上被用于修复使用克隆代码的项目,给黑客的利用提供了可乘之机。
其余研究的短板:
- CCFinder等:处理太复杂
- ReDeBug:目的是为了大规模、快和准确,但实际效果并不行
- SourcererCC:容易找到已修补的克隆代码
VUDDY(VUlnerrable coDe clone DiscoverY)…(这名字取的真刻意):
- 函数粒度识别
- 正则化使得其漏洞模式(也就是漏洞函数)存在一定通用性
- 二级索引:长度+hash,使得其更快
- 效果:1764个patch中找到5664个漏洞函数,从25253个C/C++项目中找到了133812个漏洞函数(1 day),比ReDeBug快2倍,having no false positive with Android firmware. Meanwhile, ReDeBug had 17.6 % false positives.
本文贡献:
- 工具VUDDY
- 漏洞模式抽象
- 自动化漏洞信息获取
- 开放服务, https://iotcube.net/,我试用过,做的还是很不错的,但是要自己用VUDDY开源的代码处理。然后提交hash文件检测。
#
Taxonomy#
克隆代码分类:
- Type1:完全克隆,无修改
- Type2:重命名克隆,例如类型名,函数名,变量名等
- Type3:简单的增删等
- Type4:语义克隆
其中VUDDY支持类型1和类型2的检测
代码粒度分类:
- token
- line
- function
- file
#
根据粒度来讲
- token-level:CCFinder(我用过不好用)、CP-Miner
- line-level:Redebug(好用)
- function-leve:SourcererCC(好用)
- file-level:DECKARD、FCFinder
- Hybrid granularity:VulPecker
Problem and goal statement#
Problem formulation#
克隆检测定义:从一个代码项目中,判断函数是否存在
完全克隆定义:$C(f)=1$
抽象克隆定义:

Goals#
设计一个能检测1、2类克隆的算法
The proprosed method:VUDDY#
VUDDY的框架如下图所示:
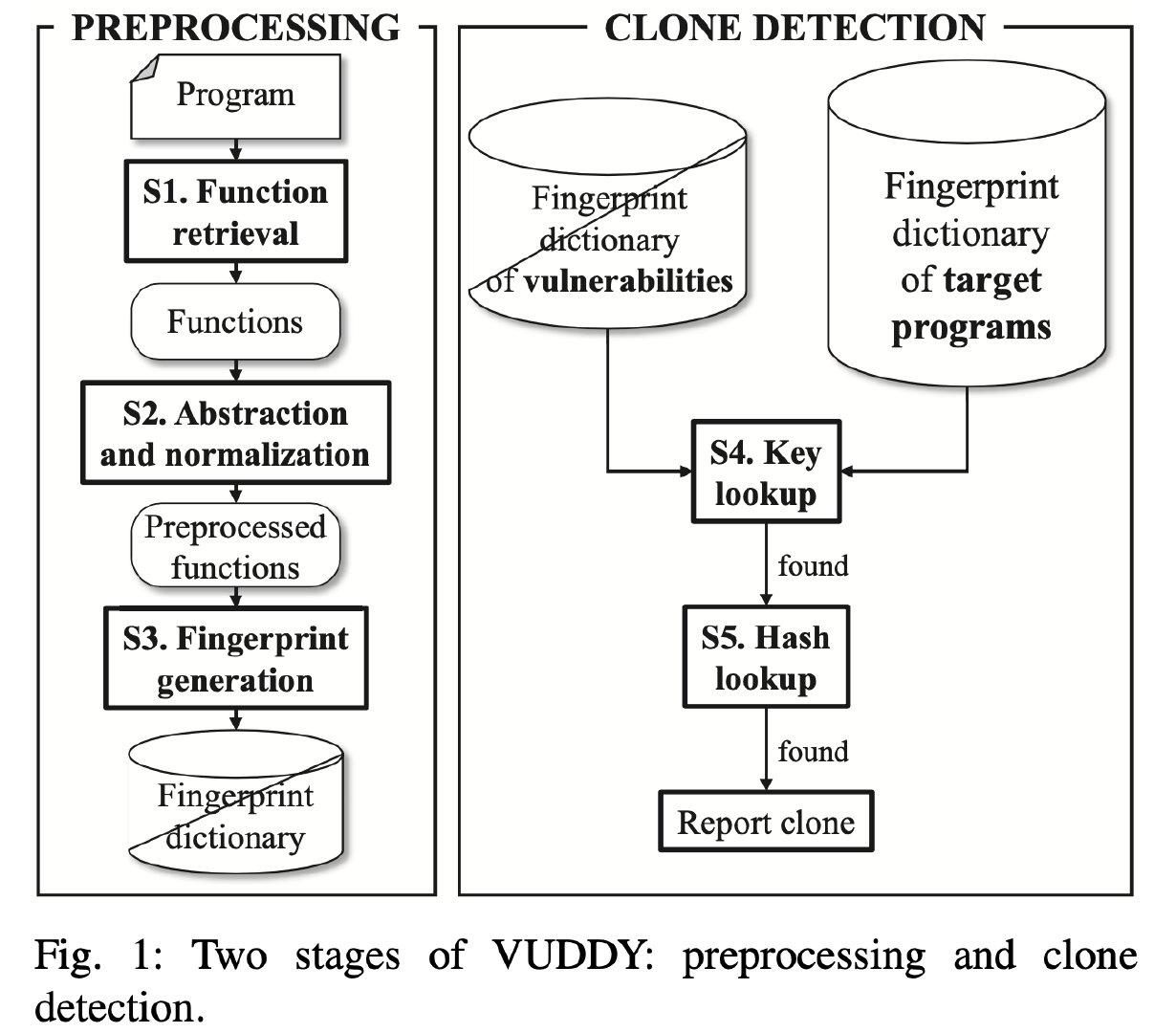
分为两个部分:预处理部分和克隆检测部分
预处理部分:
- 函数提取
- 抽象和正规化
- 漏洞指纹生成
克隆检测部分:
- key查询
- hash查询
Preprocess#
Function retrieval:使用ANTLR实现了一个提取C程序中的函数的jar包,并提取参数、类型、局部变量信息
Abstraction and normalization:对参数、类型、局部变量进行正规化,(统一用某个字符串代替),可以分为不抽象、参数抽象、局部变量抽象、数据类型抽象、函数调用抽象,见下图

Fingerprint generation:计算函数体以长度和hash值,示例见下

Clone detector#
key lookup: 长度过滤
hash lookup:hash比对
由于用了两层索引,速度很快,最差是O(n)
Application:Vulnerability detection#
Establishing a vulnerability database#
- Git clone
- git log --grep=‘CVE-20’
- Git show commit
- Filter irrelevant commits.
- git show the old file ID
通过这种方法找到了9779个漏洞不行,对CVE去重后的1764个补丁中找到了5664个扣动函数
Vulnerability detection#
和clone detector没啥差别,但是是集合和集合间的交叉搜索
Implememtation#
- ANTLR实现函数提取部分
- hash选用md5
- 字典选用python的
dict[Length]=[hash1,hash2..]
Evalutaion#
实验环境:
- Ubuntu16.04
- 2.40 GHz Intel Zeon
- 32GB RAM
- 6TB HDD
*数据集: 从2016.1.1到20167.28 github上的 25253个C/C++ git项目
比较的配置:

大数据量比较: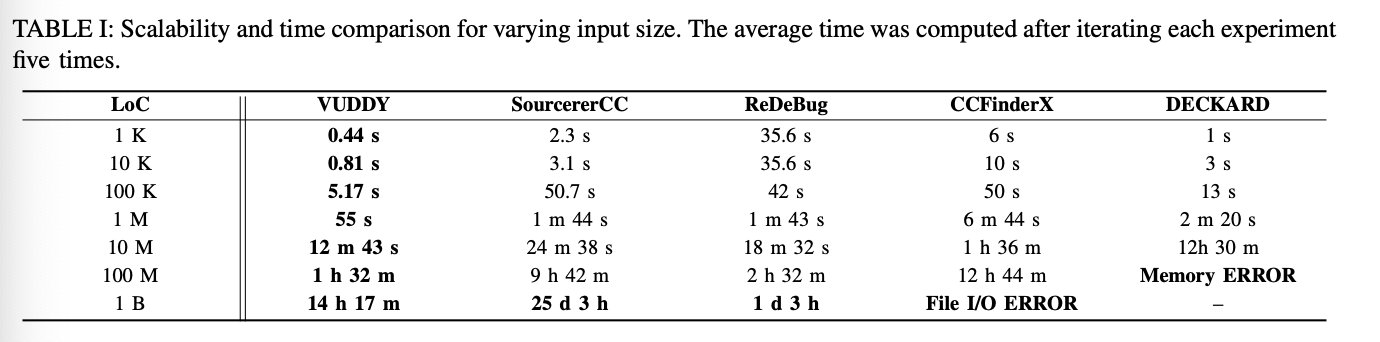
准确率比较: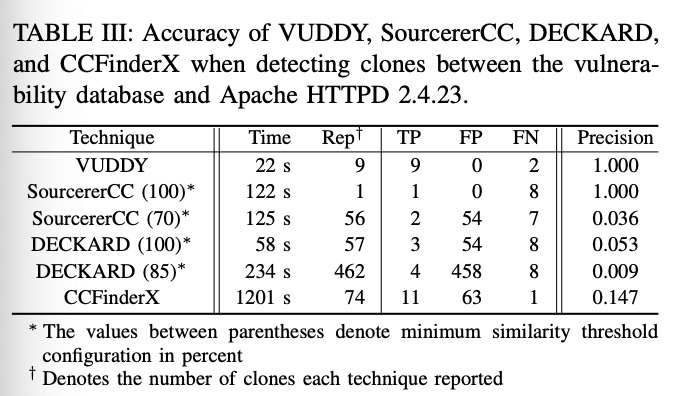
完全克隆检测和抽象比较: 166个 VS 206个,后者比前者多了24%的结果
Compare with redebug#
- twice faster
- less false positive
- VUDDY可以检测第二类但是ReDeBug不行
具体的分析就不说了
Discussion#
讨论了函数粒度的优势,包括时间复杂度、内存使用以及精度
个人看法#
- 与redebug相比,把粒度加大到函数,错误率与redebug相比会降低很多
- 当redebug的窗口设置为函数体大小时,就等于不进行正规化的VUDDY
- 从使用效果来看,其实还是有部分误报情况的,准确度和具体的项目有很大关系

