面向任务的对话系统
在对话系统领域中,面向任务的对话系统是其中很重要的一个分支,不同于开放域的对话系统,任务型对话系统侧重于完成一个领域或者几个领域内的特定任务,例如天气查询、餐厅预订等。面向任务的对话系统能够分为pipeline方法和end-to-end方法两类,并依赖相关领域内的知识库。本文首先介绍pipeline和end-to-end两类方法,然后简单介绍在面向任务的对话系统研究中使用的数据集,最后结合近三年中面向任务的对话系统领域内的研究成果,梳理当前存在的主要挑战。
pipeline的方法#
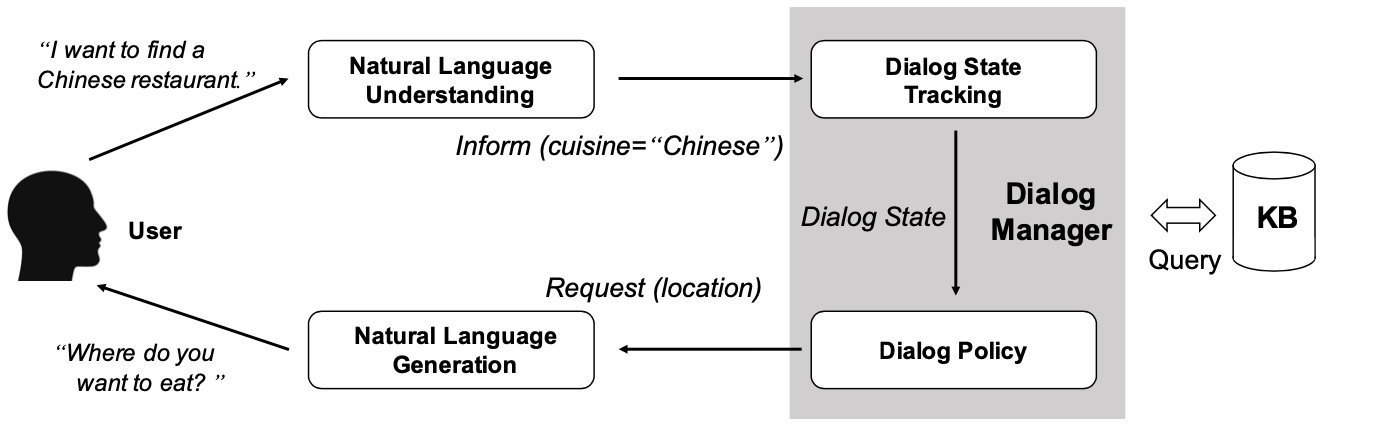
图1.1所示为基于pipeline的面向任务的对话系统结构,它由自然语言理解(NLU)、对话状态跟踪(DST)、对话策略学习和自然语言生成(NLG)这四个关键部分组成:
(1) 自然语言理解:将用户的自然输入,生成预定义的语义槽。
(2) 对话状态跟踪:管理每个回合的对话输入和之前的对话历史,并输出当前的对话状态。
(3) 对话策略:根据当前的对话状态学习下一个动作。
(4) 自然语言生成:根据对话策略生成的动作,将其映射到自然语言,生成对话系统的响应。
end-to-end的方法#
传统的面向任务的对话系统需要许多领域内的人工干预(例如手工编写规则、提取特征),这导致在一个领域中表现很好的方法在另一个领域中应用时不容易快速适应。对于pipeline的方法,主要存在两个问题:第一个问题是是信用分配问题(credit assignment problem),最终用户的反馈很难传播到每个上游模块。第二个问题是组件之间的相互依赖。一个组件的输入取决于另一个组件的输出。当一个组件适应新环境或用新数据重新训练时,所有其他组件都需要相应地调整,以确保全局优化。
与pipeline的方法不同,end-to-end的方法使用单个模块并与结构化的外部知识库进行交互,目前使用的方法有基于神经网络、强化学习等。
常用数据集#
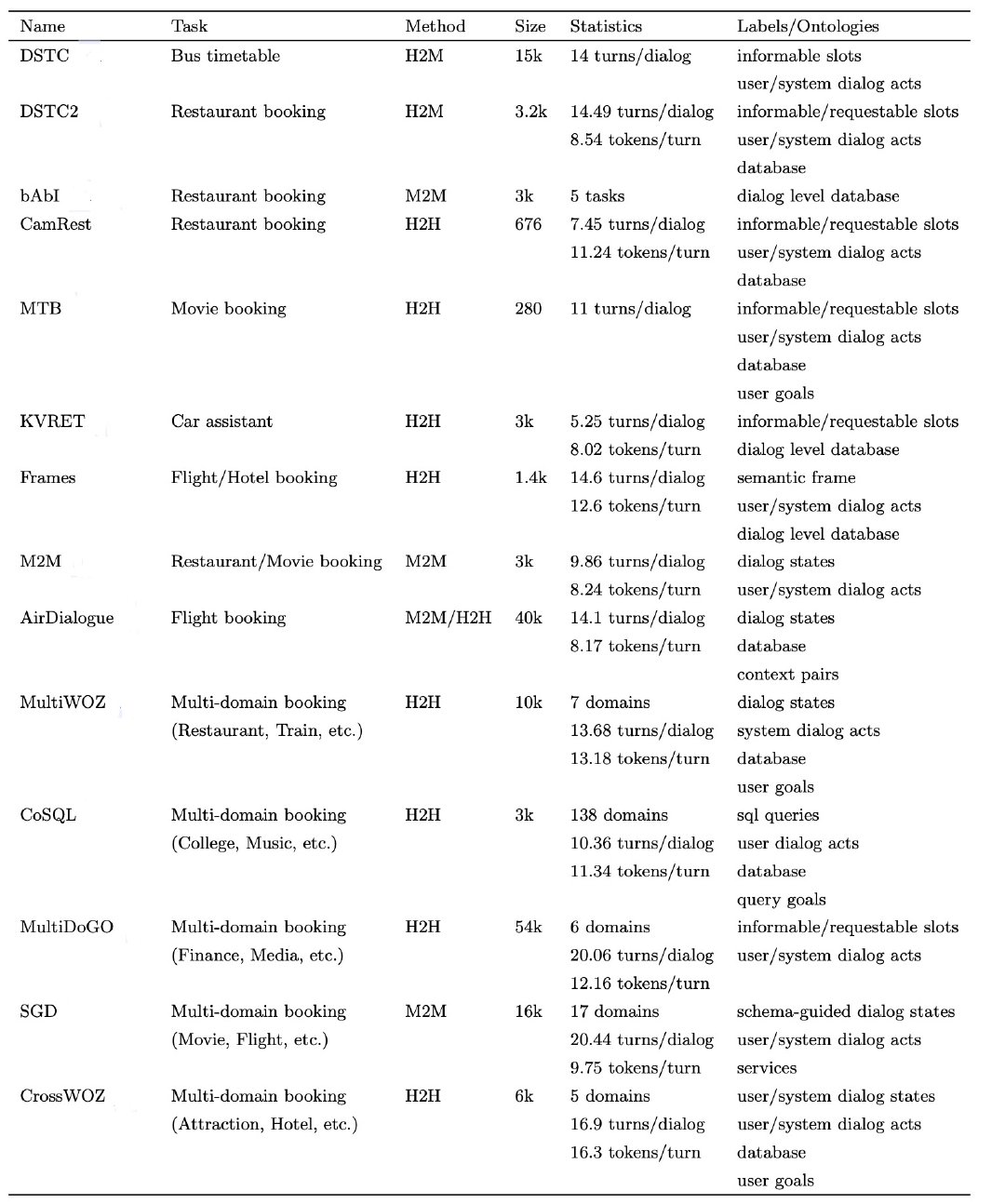
DSTC:提供了第一个用于对话状态跟踪的通用测试平台和评估套件。
DSTC2: 在对话状态跟踪任务中引入了一些其他功能。对话状态也使用更加丰富的表示形式,包括用户目标的slot-value属性等,在交互过程中,存在一个匹配实体的数据库。
bAbI:设计用于五个面向任务的对话任务。这些任务以基础知识库为基础,涵盖多个对话阶段,并评估模型的功能,包括对话管理、知识库查询等。
CamRest:应用了WOZ范式,是测试一个回合,数据相对干净
MTB:通过Amazon Mechanical Turk收集并由专家注释,常用于强化学习方法评估
KVRET:内容包含车内助理的三个领域(日历调度、天气检索和导航),对话通过知识库建立,因此十分适合构建能够使用知识进行推理的模型
Frames:为了研究面向任务的对话系统的存储能力以及如何向用户提供知识库信息而开发的。
M2M:通过框架收集,能够快速引导任意领域中的end-to-end对话。进通过提供任务模式和API客户端即可支持特定任务的对话。
Air Dialog:定义了一个目标驱动的对话,以一对上下文为条件,最终达到目标状态,它支持三个对话任务:对话生成、状态跟踪和对话重现。
MultiWOZ:是一个跨七个领域的大型语料库,每个对话都由一系列对话状态和系统动作进行注释。
CoSQL:用于构建通用的知识库查询对话系统,每个对话都模拟了实际的知识库查询场景。
MultiDoGo:是一个大型对话数据集,带有意图类型和slot标签。
SGD:研究了模式指导的方法,能够轻松集成新的服务和API。
CrossWOZ:第一个面向任务的中文数据集,着重于跨领域的用户目标。数据集包含了丰富的对话状态及用户和系统对话行为标签,以及用户模拟器和几个基准模型。
近期研究和存在挑战#
从对pipeline的方法和end-to-end的方法介绍中可以看到,在面向任务对话系统中,存在的问题主要有以下三个[1]:
(1) 数据有效性问题:特定领域内数据的收集和整理需要耗费大量的人力和时间,因此需要提高已搜集领域数据的有效性。
(2) 多轮对话策略问题:在多轮对话中,对话策略强调目标导向,在每一轮中的系统动作应该和之前的对话保持一致,因此通过对多轮对话策略的研究,能够有效提提升多轮对话中对话系统的性能。
(3) 知识库整合问题:任务型对话系统通过查询知识库检索实体生成响应,在pipeline的方法中,查询根据对话状态跟踪模块的结果进行构造,而在end-to-end的方法中,如何有效整合知识库内容进行应答是一个问题。
以下根据上述三大挑战,对近三年来面向任务的对话系统的主要研究进行梳理。
对数据有效性问题的研究#
近几年的研究工作在数据有效性问题上,都选择先找出不同领域间共有的数据进行较为通用的学习,并在迁移到新领域内时进行领域内特有数据的学习,从而提高已有数据的在其他领域内的有效性。
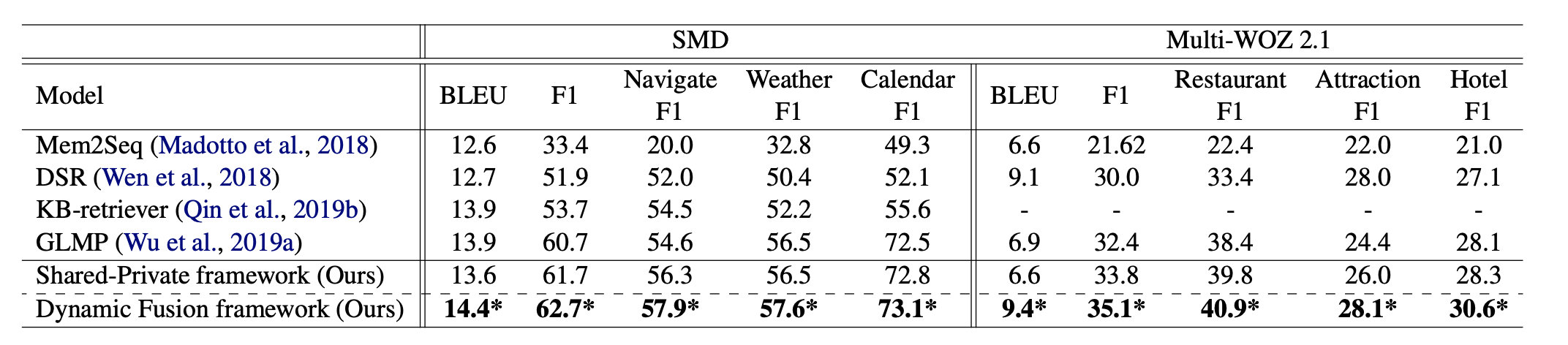
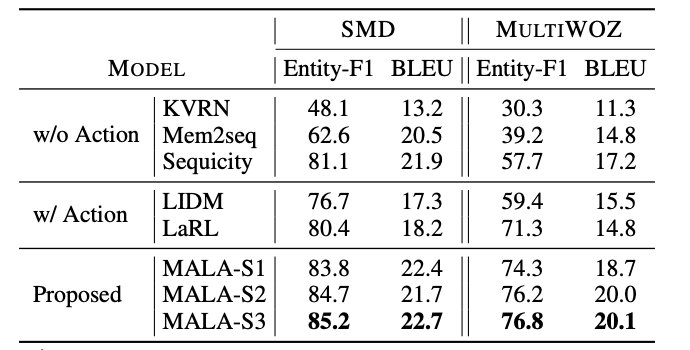
对多轮对话策略的研究#
在多轮对话时,对话管理模块不仅需要处理当前对话,也要处理之前的历史对话,因此对于对话策略的研究能够在多轮对话中提高对话系统的性能。
Lei W等人[5]提出了Sequicity模型(图4.3),将面向任务的地话系统中的状态跟踪和文本生成通过sequence-to-sequence完成,并提出了Two Stage CopyNet模型,减少了计算的复杂度。实验表明,该方法在大规模预料库中优于baseline并且能够较好的处理OOV(Out of Vocabulary)问题(图4.4)。
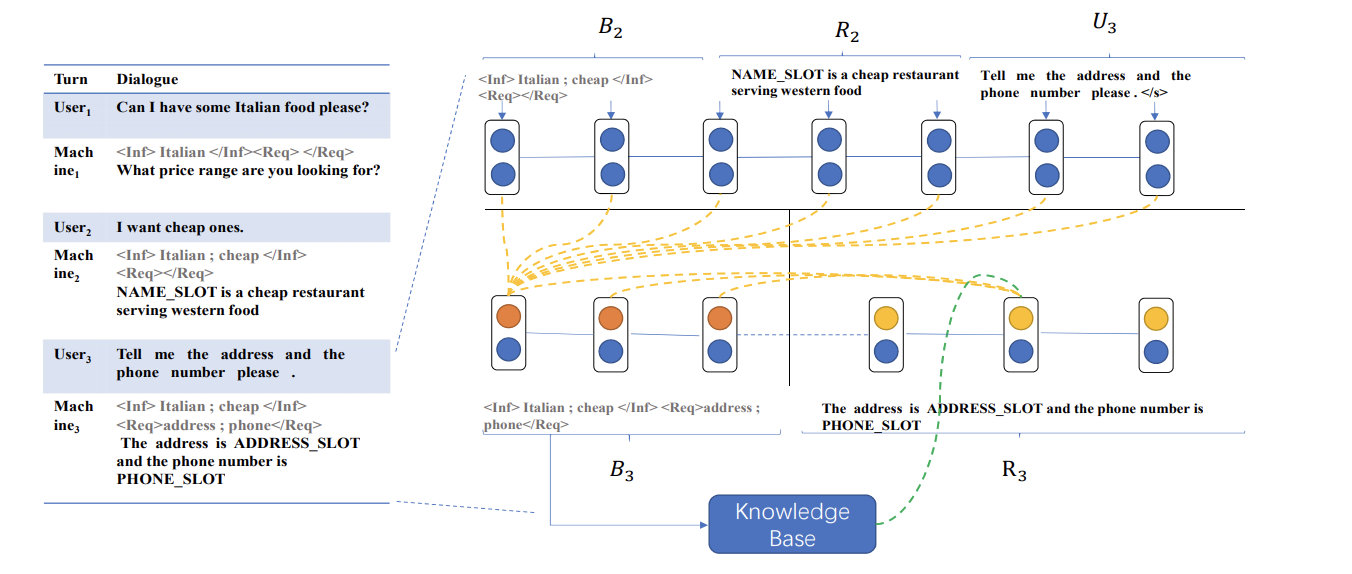
(1) 第一步: 根据上一轮对话的belief span,上一轮对话的response和本轮的对话内容,生成本轮对话的belief span。
(2) 第二步:在生成response时,根据上一轮对话的belief span,上一轮对话的response和本轮的对话内容,本轮的belief span和知识库获得本轮的response。

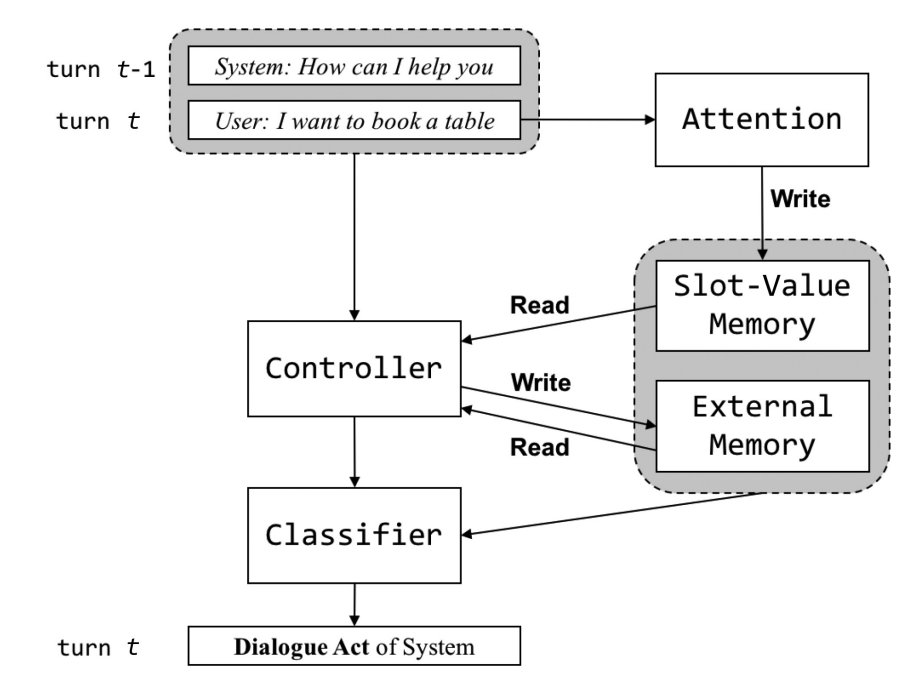
对知识库整合问题的研究#
在end-to-end的方法中,如何有效的利用知识库的知识整合到模型中是一个问题,在之前的RNN编解码器模型和结合Attention机制的RNN编解码器模型中,都存在以下问题:(1) 希望将外部知识库整合进RNN隐藏层中,但RNN处理长序列不稳定;(2) 处理长序列十分耗时,尤其是在加入了Attention机制的情况下。
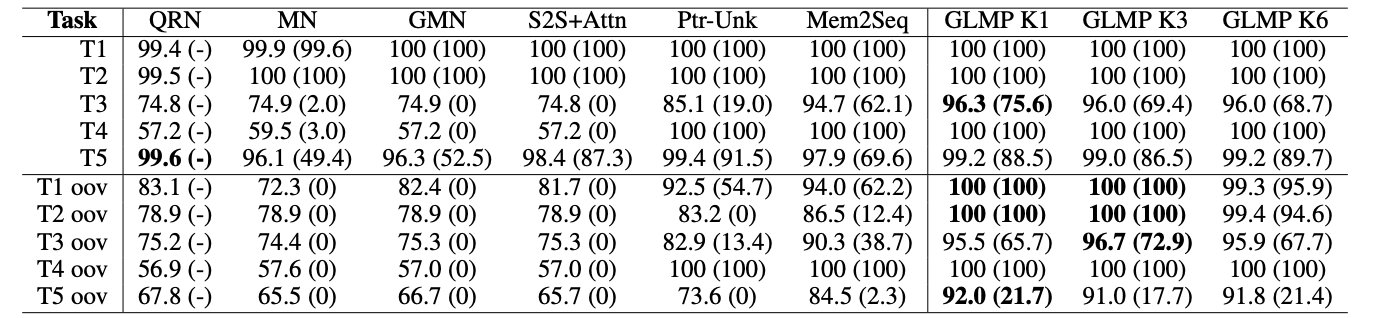
为了解决这一问题,Madotto A等人[7]在MemNNs的基础上提出了Mem2Seq模型,并使用multi-hop attention机制和pointer network。其优点有:(1)能够有效的融入知识库信息;(2)能学习如何生成动态查询来控制内存访问;(3)训练速度更快并在bAbI、DSTC、In-Car数据集上的表现优于之前的模型(图4.7)。
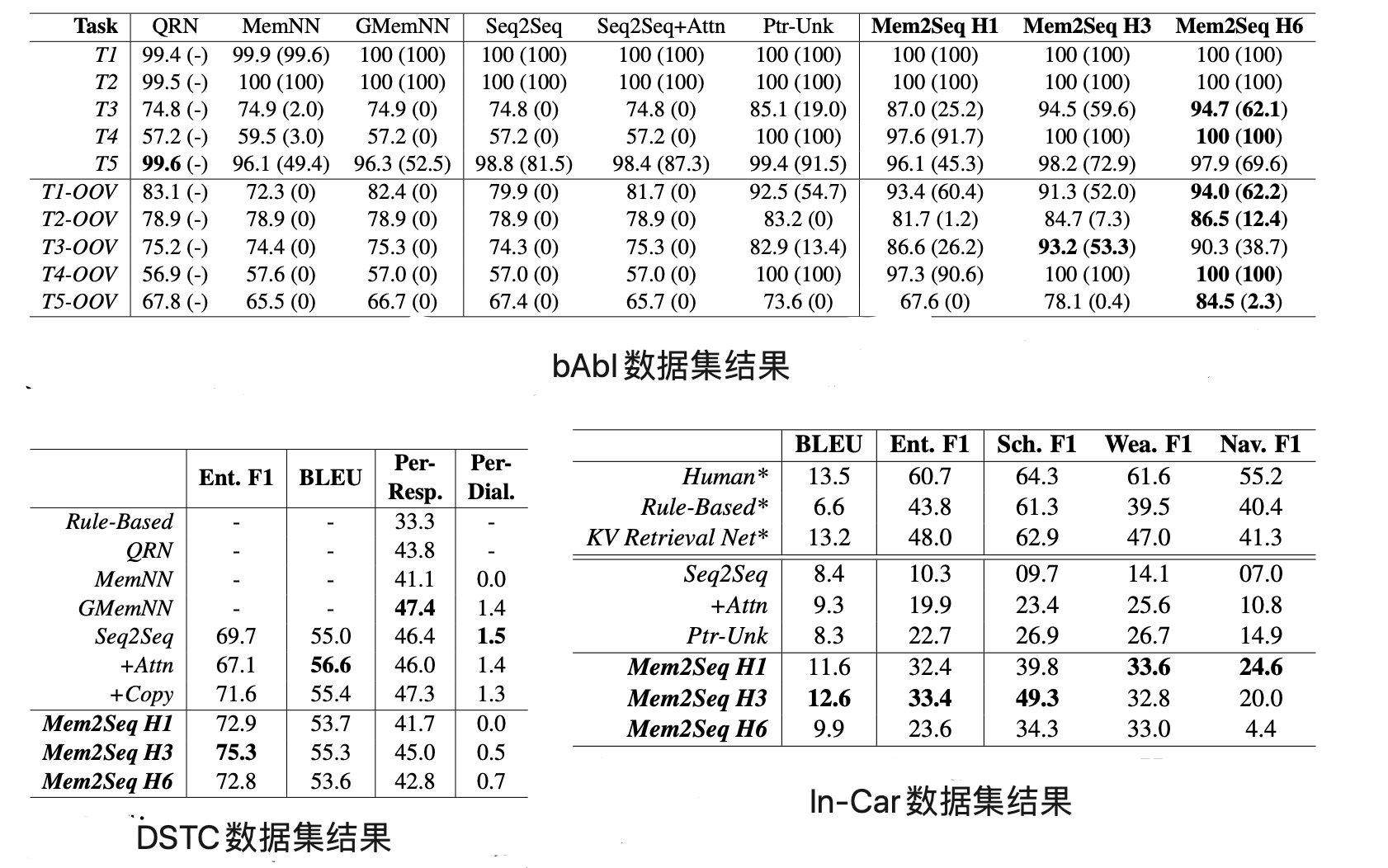

从对近年面向任务的对话系统研究的梳理和回顾中可以发现:
(1)在对数据的有效性问题的研究中,如何提高已有数据在新领域中有效性,减少人工构造新领域的数据量是一个热点和挑战。目前通用对话预训练结合新领域少量数据调优是主要的方法,在扩展到新领域时,结合领域间共有的隐式知识取得了比较好的效果。
(2)在对多轮对话管理问题的研究中,则主要研究如何在多轮对话中,更好的结合历史对话内容,提高全局的对话系统性能。
(3)在end-to-end的方法中对结合知识库问答问题的研究中,目前的研究主要还是在MemNNs的基础上对Memory机制进行改进,通过各种方法结合知识库知识和对话上下文给出更好的对话回答。
总体来说,面向任务的对话系统的研究仍有较长的路要走,我相信终有一天面向任务的对话系统能够完全代替人类进行任务型对话。
参考文献#
- [1] Zheng Zhang, Ryuichi Takanobu, Minlie Huang, Xiaoyan Zhu. Recent Advances and Challenges in Task-oriented Dialog System . arXiv preprint arXiv:2003.07490. 2020
- [2] Henderson M, Vulić I, Gerz D, et al. Training neural response selection for task-oriented dialogue systems[J]. arXiv preprint arXiv:1906.01543, 2019.
- [3] Qin L, Xu X, Che W, et al. Dynamic Fusion Network for Multi-Domain End-to-end Task-Oriented Dialog[J]. arXiv preprint arXiv:2004.11019, 2020.
- [4] Huang X, Qi J, Sun Y, et al. MALA: Cross-Domain Dialogue Generation with Action Learning[J]. arXiv preprint arXiv:1912.08442, 2019.
- [5] Lei W, Jin X, Kan M Y, et al. Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence architectures[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 1437-1447.
- [6] Zhang Z, Huang M, Zhao Z, et al. Memory-augmented dialogue management for task-oriented dialogue systems[J]. ACM Transactions on Information Systems (TOIS), 2019, 37(3): 1-30.
- [7] Madotto A, Wu C S, Fung P. Mem2seq: Effectively incorporating knowledge bases into end-to-end task-oriented dialog systems[J]. arXiv preprint arXiv:1804.08217, 2018.
- [8] Reddy R, Contractor D, Raghu D, et al. Multi-Level Memory for Task Oriented Dialogs[J]. arXiv preprint arXiv:1810.10647, 2018.
- [9] Wu C S, Socher R, Xiong C. Global-to-local memory pointer networks for task-oriented dialogue[J]. arXiv preprint arXiv:1901.04713, 2019.

