Beyond Free Riding-Quality of Indicators for Assessing Participation in Information Sharing for Threat Intelligence
依然是态势感知作业需求
Abstract#
paper针对在威胁情报共享体系中,某些参与者为了获得共享情报,却又不给出实质性的贡献的情况(所谓搭便车),提出指标质量QoI来评估参与者的贡献,并引入了以下度量:正确性、相关性、实用性和唯一性。
采用基准方法定义了质量度量,然后获得了一个参考数据集,并利用机器学习文献中的工具进行质量评估。将这些结果与仅将信息量视为贡献度量的模型进行了比较,揭示了各种有趣的观察结果,发现低质量的参与者。
Introduction#
在建立共享体系过程中,参与者之间也存在着竞争关系,所以有的参与者只想加入但不想有实质性的贡献。所以有了作者的这个工作
Quality of Indicators#
一个定义良好的QoI系统能够区分参与者的贡献度,提高社区质量。由于在社区中,并不是强制性的要求共享,全凭意愿。因此我们需要一个稳健的评价系统,而不是预先定义信任。
The Simple Contribution Measures#
其他论文存在这个gap,因此确定QoI来捕捉搭便车现象存在必要。
仅仅通过成员贡献的数目来衡量贡献度是不够的,在以往的文献中未提出很好的贡献质量评价标准。
Features of Quality of Indicators#
已有的文献探讨过QoI和信息私密性(独家)、正确性(准确)、与社区成员的相关性(领域)、效用、唯一性(信息是否冗余)的关系。
除了以上,也有时效性指标。单独的使用一个指标是不够的,因此在本文中对其进行加权来评价这些指标的质量。
Contribution#
1、结果认为,在信息共享体系中,需要QoI来分析成员的贡献
2、制定了稳健的度量指标
3、通过实验演示了指标,展示了健壮性,以及它区分搭便车行为的能力
OVERVIEW AND PRELIMINARIES#
首先概述了网络威胁情报系统,然后介绍了这些系统中信息共享的独特问题,为了解决这些问题,需要采取质量评估。
The Threat Landscape#
主要讲了僵尸网络的威胁
The Need for Threat Intelligence#
主要是为了在被攻击前发现安全威胁。类似于银行没被抢之前就找到有意图的罪犯。
Threat Intelligence Sharing#
随着互联网的发展,威胁的增多,单个机构的力量很难解决所有问题。
通过威胁情报的共享,可以联合防御。
为了达成情报共享,就需要定义接口啥的来进行交换。(参考文献3、4、5定义了信息共享标准)
Risks of Sharing#
1、威胁信息的暴露,可能会被利用于攻击
2、泄露分享者的隐私信息等
3、参与者之间存在合作和竞争关系,一手情报不愿意分享
Formulation of the Free-Riding Problem#
定义搭便车行为:一些人是为了从共享信息系统获利而不是为了贡献,不肯提供有用的内容。
How Quality of Indicators Help#
这小段没啥信息量
QOI ASSESSMENT METHODOLOGY#
QoI度量包括指标相对于标签特征的正确性、指标与消费社区成员的相关性、指标的实用性及其唯一性。
QoI Metrics#
4个度量:
- 正确性
- 相关性
- 实用性
- 唯一性
System Architecture & Design#
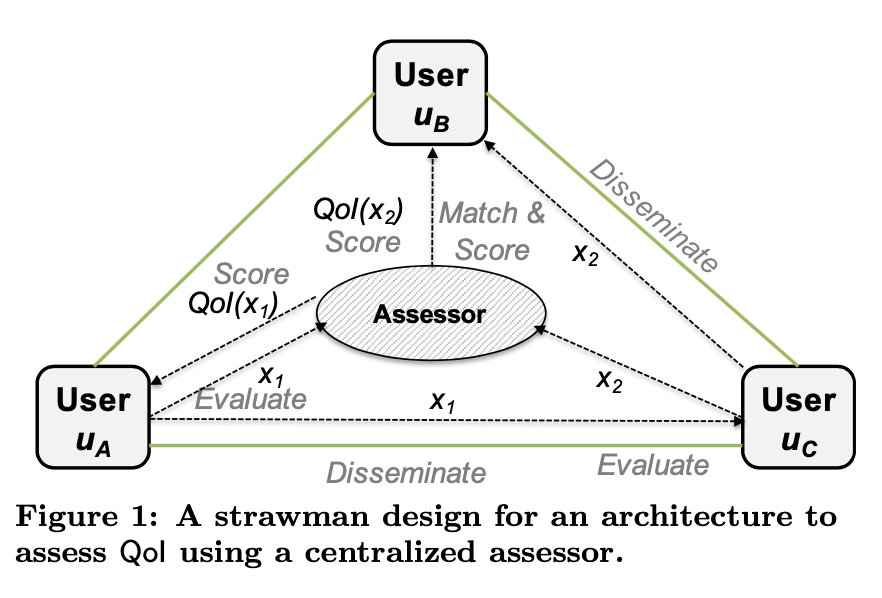
上图是大概的共享体系模型,在其中加入一个assessor,用于计算分享的信息的质量,打分
这里假设交换的信息真实且清晰可见,使用现有的信息交换协议,提供端到端的安全保证。
System Setup and Steps#
- 定义评价指标和打分程序
- 定义威胁和质量标签的注释。注释可以是指示威胁类型的标签,也可以是用于标识指标的质量(严重性,及时性等)或质量类型的标签。利用这些注释,将权重值分配给每个质量标签,并使用计分方法将质量标签转换为指标的数字总得分。
- 构建参考数据集
- 训练分类器
给定样本,用模型预测样本的标签,与参与者提供的标签对比是否匹配,结果记录为质量批注,计算置信度
整体过程如下如所示
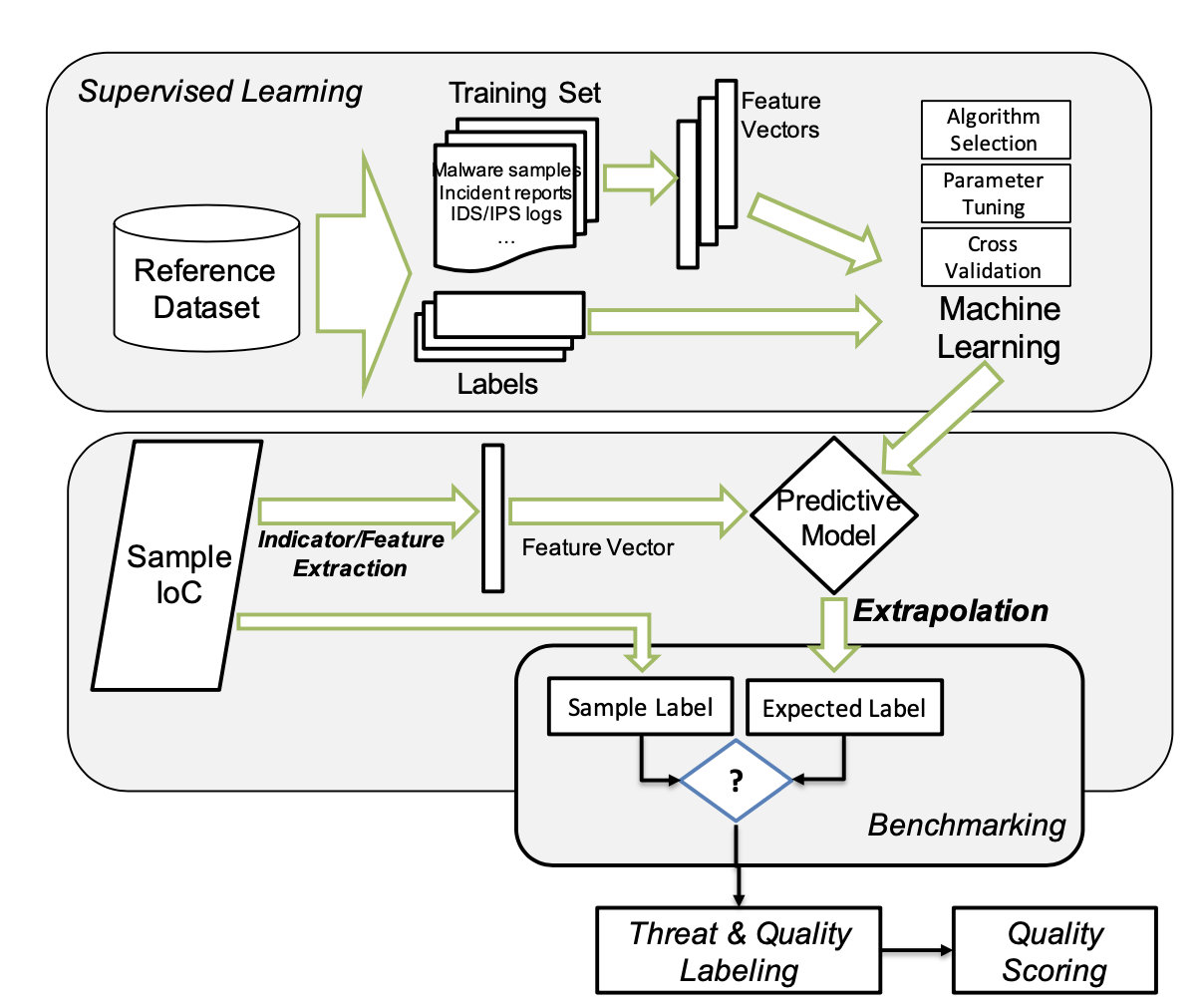
QoI Assessment Process Operation#
训练使用有监督学习算法,整体过程包含特征选取、机器学习算法的选取、参数矫正(正则化等)、交叉验证
QOI ASSESSMENT PROCEDURES#
是对前面步骤的详细说明
Reference Dataset and Learning#
主要以VirusTotal作为参考,可信度高且信息量充足、其内容十分有用。
Extrapolation and Benchmarking#
在有了初始的参考后,需要考虑的是如何使用参考数据集来评估和推断指标的值和质量。在paper中使用半监督学习来解决这个问题。
分类模型:nearest centroid classifier (NCC)最近质心分类器
找了个图,大概这样

Labeling and Quality Scoring#
有了分类器,然后需要参与者给出提供信息的feature和label,就能进行预测和打分了。
Correctness#
计算正确性
如果预测出来的标签和参与者提供的标签匹配,就给一个正分数,然后最后加权平均得到结果分数

Relevance#
计算相关度

对于公众更感兴趣的label,赋予更大的权值
Utility#
计算效用

Uniqueness#
计算唯一性

Quality of Indicator (QoI)#
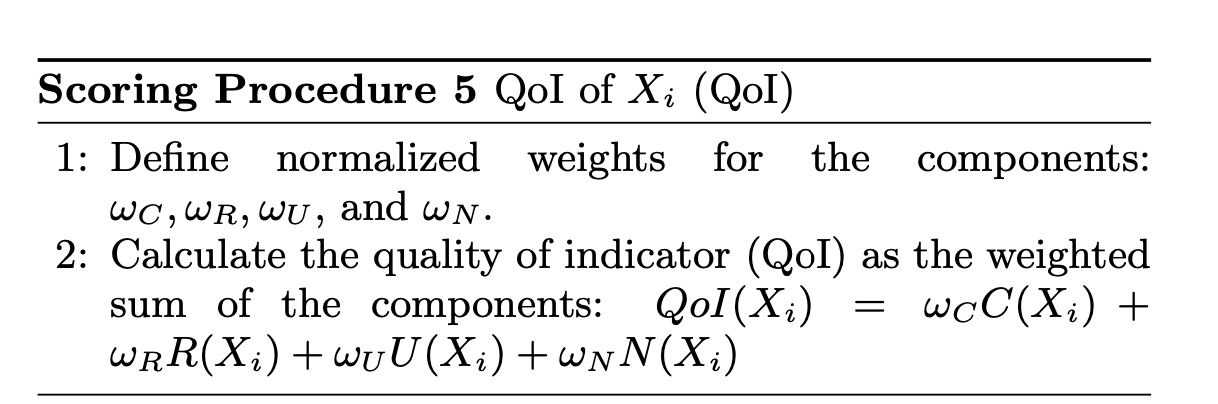
EVALUATION AND FINDINGS#
和传统的只看数量方法进行比较
Dataset Characteristics#
为了突出QoI作为评估威胁情报信息共享贡献的新概念,我较了基于质量和基于数量的评分方法对AV供应商贡献的差异。为此,我们的数据集列举了在2011年年中至2013年年中的数据收集期间,向VirusTotal提交恶意软件样本(包括标签)的AV供应商
评估的一个关键目标是证明在使用基于数量的分数计算的不足,因为一个供应商可以通过提交大量关于低质量恶意软件样本的信息来获得高评级。如前所述,这可能是由于以下几个原因造成的:提交的关于某些恶意软件样本的工件不正确,样本族不准确,或者提交的关于样本的信息类型无助于识别或检测它们。
Result#
就是几个图,结论也很清楚

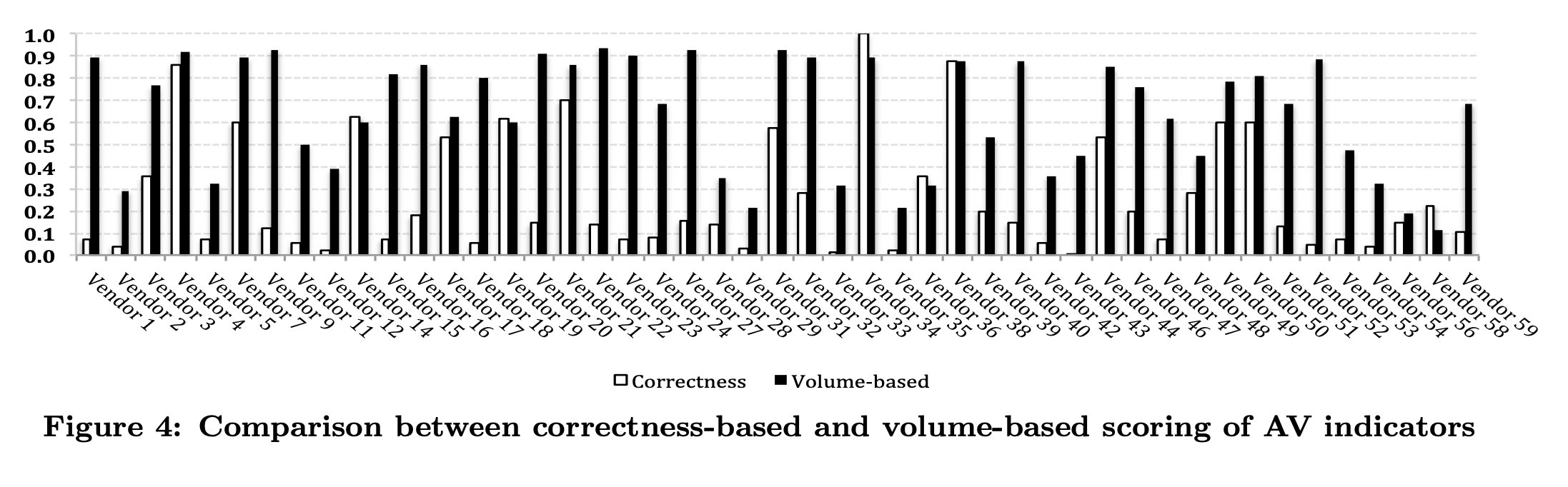
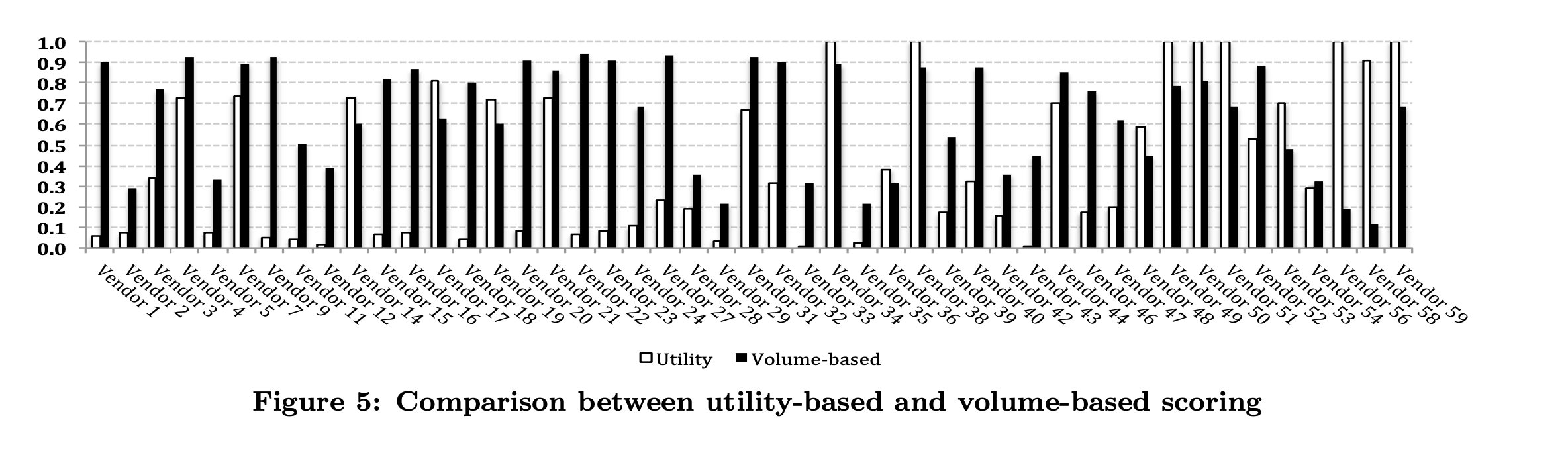

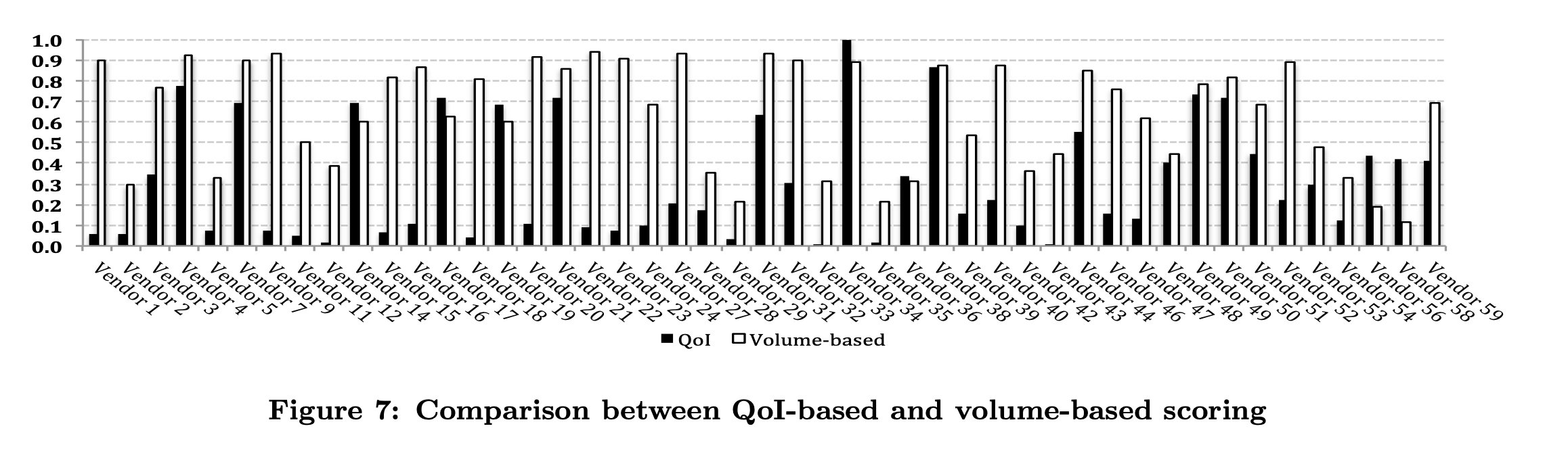
可以看到有很多公司在划水23333
感想#
虽然这个工作得出了有意思的结论,但其实存在一些不恰当的地方,在计算特征的时候,提到了权重,看样子都是作者自定义的,不太科学,更好的方法是通过使用ground truth,利用数值化的方法来计算出来(比如一般来说,我们知道出现次数越多的label一般是人们比较感兴趣的,可以通过计算频率来算权重,代替认为指定)。

