Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection(AAAI 2020)
二进制代码相似性检测:在没有源代码的情况下检测相似的二进制函数。传统的方法一般使用图匹配算法进行检测,但传统方法准确率低且复杂度高。深度学习的发展为这一领域提供的新的方法,根据控制流图生成CFG,并使用GNN计算图嵌入,既高效又准确。本文提出Semantic-Aware Neural Networks ,取得了不错的成果
Introduction#
2017年有学者提出了Gemini网络(Gemini不是QG前主教练吗hhhh)
Gemini首先将CFG使用人工定义的特征,将CFG中的块表示为低维特征。然后使用Structure2vec生成图前嵌入。最后使用siamese计算两个二进制函数的相似度得分并使用梯度下降训练模型。
但Gemini也有一些不足之处:1.它表示使用的向量只有8维,因此会损失很多语义信息;2.节点的顺序是很重要的一个信息,但它没有考虑。
为了解决上面两个问题:本文使用了包含以下三个组件的框架:semantic-aware模块、structural-aware模块、order-aware模块。
在semantic-aware模块中,使用NLP的方法对二进制函数的语义进行提取,将token看成word,block看成sentense。文中使用bert进行训练
在structural-aware模块中,使用MPNN计算CFG的图信息
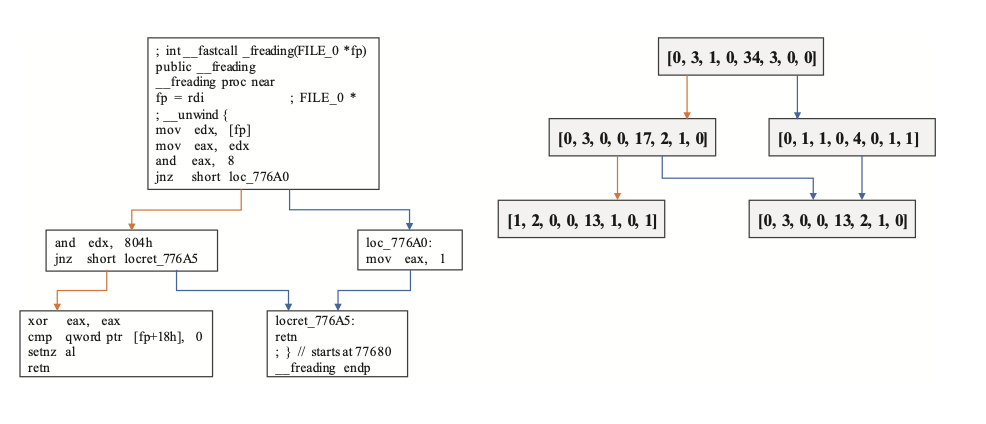
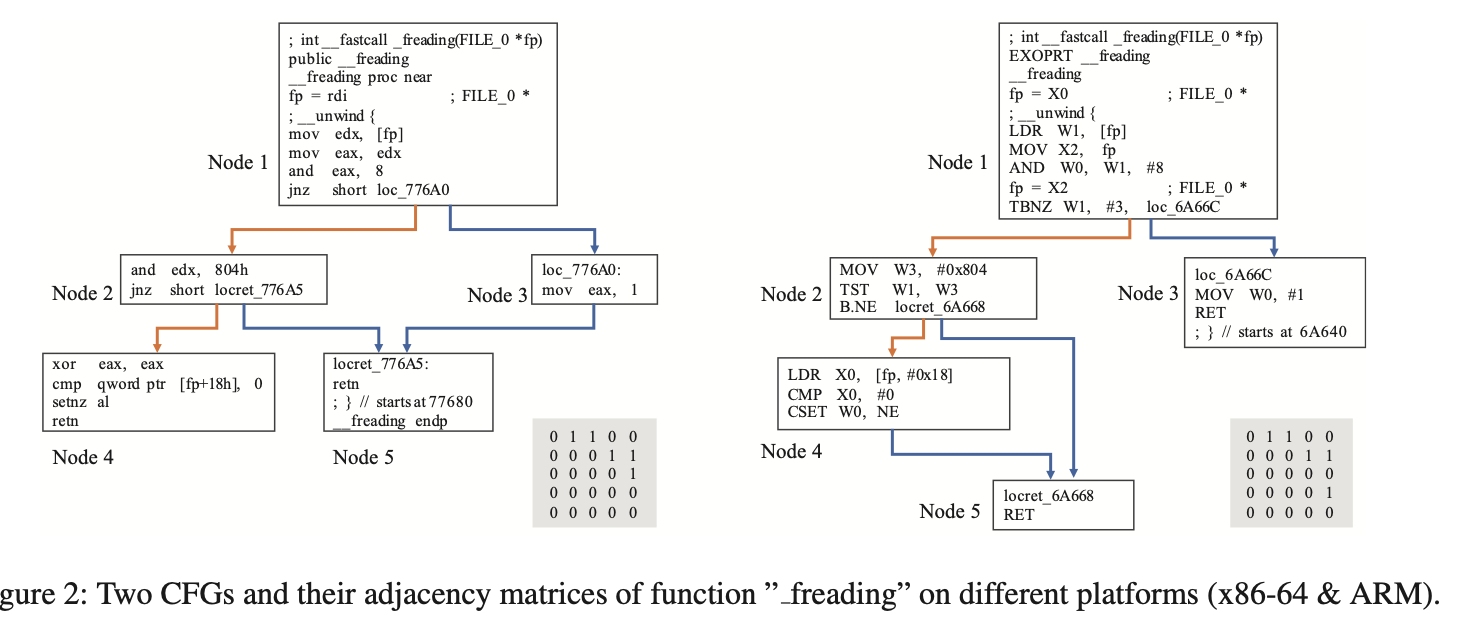
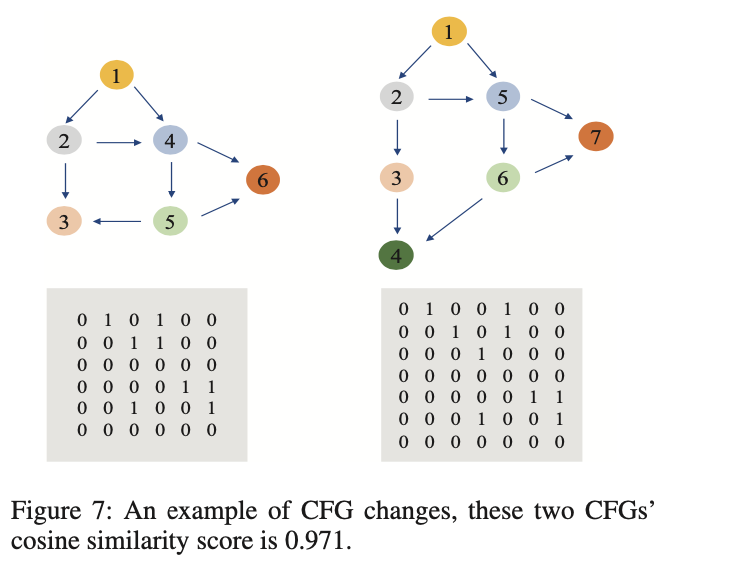
在order-aware模块,主要是提取节点的顺序信息。如下图,是在不同平台编译的同一函数的CFG,可以看到它们的Node1都与Node2和Node3连接。Node2都与Node4和Node5连接。这个相似性可以从它们的邻接矩阵中很容易看到。
贡献:
- 提出了能进行二进制相似性识别的框架
- 在semantic-aware模型中使用Bert进行预训练,并分割成MLM、ANP、BIG和GC四个子任务
- 在order-aware模型中,使用CNN检测邻接矩阵的相似性
#
- Xu等人 Gemini 2017:使用图嵌入,效果好于传统方法,但手动选择特征进行块表示,包含的语义信息不足够
- Zuo等人 2018:使用LSTM,将token看成word,block看成句子,使用LSTM进行语义表示,确保相同的块,语义表示也相同。缺点:1.训练数据太依赖专家经验;2.不同的平台需要进行单独训练和数据的收集
Model#
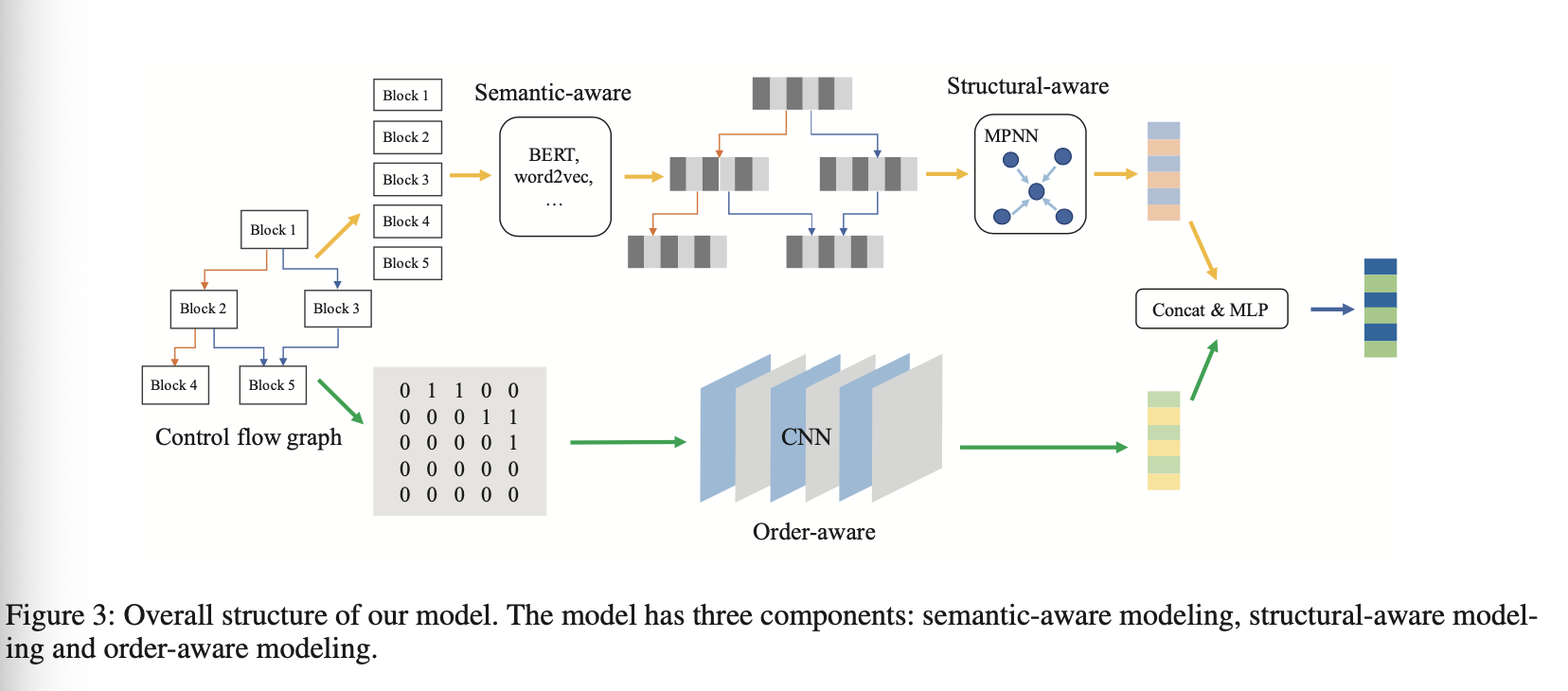
总览:
可以看到上下两条路径。上面的路径输入时去掉了CFG的流信息,只使用块作为输入,在Semantic-aware模块中获得block embedding,然后通过Structual-aware模块获得graph embedding和structual embedding。在下面的路径中使用CFG的邻接矩阵作为输入,得到图的顺序信息,最后使用concat+MLP获得函数的表达。
$$G_{final} = MLP([G_{ss},G_o])$$
其中$G_{ss}$是上面得到的图嵌入信息,$G_o$是下面得到的图嵌入信息。
Semantic-aware 模块#
在Bert预训练模型中,主要完成四个任务,这有很多好处:1.可以从不同架构、不同平台、不同优化选项下的CFG中得到block embedding;2.在预训练过程中,我们可以得到token、block、graph粒度下的信息(因为有token level、block level和两个graph level任务);3.不需要需改编译器等来获得相似的块。
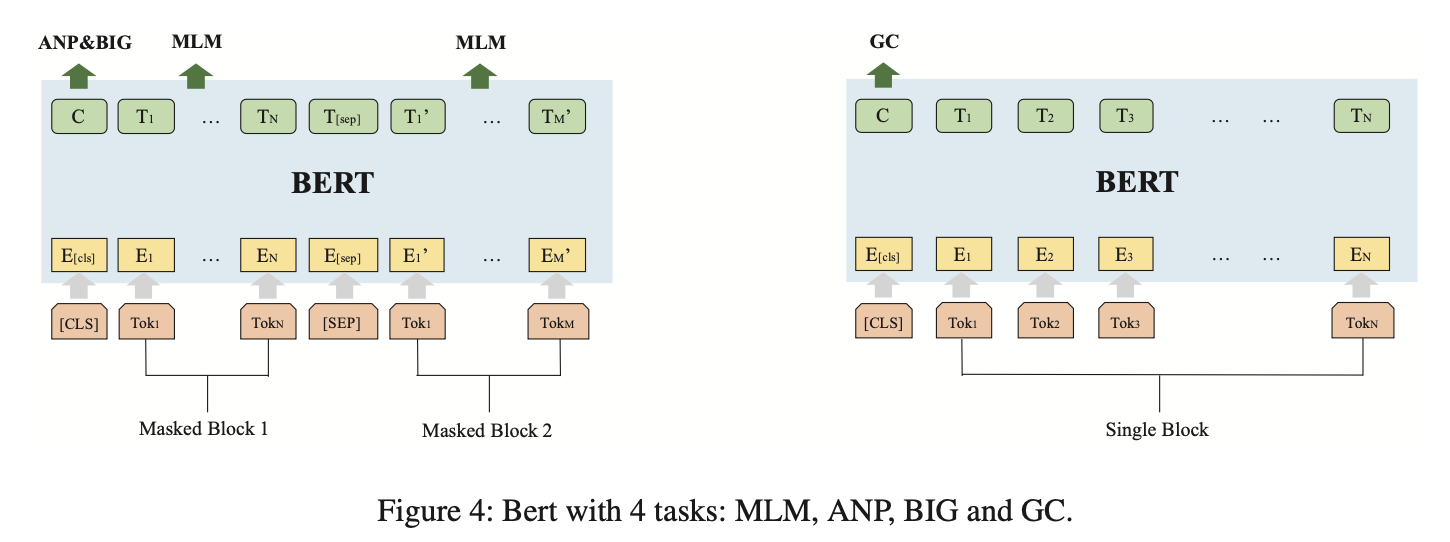
从上图可以看到Bert预训练时要完成的4个任务。
- MLM是一个token-level的任务,对block中的token进行mask操作并进行预测
- ANP任务是一个block-level的任务,控制流图是一个有向图,有节点的拓扑顺序,将控制流图中的所有相邻节点提取出来,当作相邻的“句子”。这些相邻的block pair作为ANP任务的正例,并随机选择同图内不相邻的block pair作为负例。
- BIG是一个graph-level的任务,目的是让模型判断两个block是否在同一个图中。
- GC是一个graph-level的block分类任务,在不同平台、不同编译器、不同优化选项的条件下,得到的block信息有所不同,因此希望模型可以让block embedding中包含这种信息。GC对block进行分类,判断block属于哪个平台,哪个编译器,以及哪个优化选项。
Structural-aware 模块#
在有了Bert的结果后,在这一模块中使用MPNN计算graph semantic和 structural embedding。MPNN包含三个步骤:message function M、update function U 、readout function R,经过T次后获得最终的graph embedding和structual embedding。
$$m_{v}^{t+1}=\sum_{w \in N(v)} M_{t}\left(h_{v}^{t}, h_{w}^{t}, e_{v w}\right)$$
$$h_{v}^{t+1}=U_{t} (h_{v}^{t}, m_{v}^{t+1} )$$
$$g_{s s}=R\left(h_{v}^{T} \mid v \in G\right)$$
其中$G$指整个图、$v$代表节点、$N(v)$代表邻接节点、$h_v^t$代表$t$时刻的block embedding。在文中,$M_t$使用$MLP$、$U_t$使用$GRU$、$R$使用$MLP$。
Order-aware 模块#

在这一模块中使用CNN模型,主要是为了学习到CFG中的平移不变性(借鉴计算机视觉领域)
在模型训练中,使用11层的Resnet结构,包含3个residual block,所有的feature map大小均为3*3。之后用一个global max pooling层,得到graph order embedding。在此之前不用pooling层,因为输入的图的大小不同
$$g_o = MaxPooling(ResNet(A))$$
Evalutaion#
实验主要检验方法的跨平台能力和跨优化选项能力。
Task1:跨平台二进制代码相似度分析
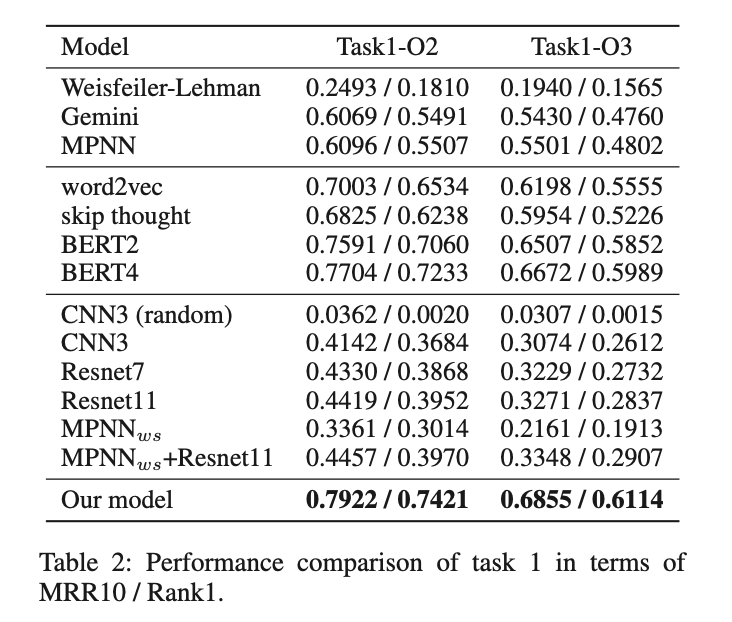
Task2:判断优化选项的能力
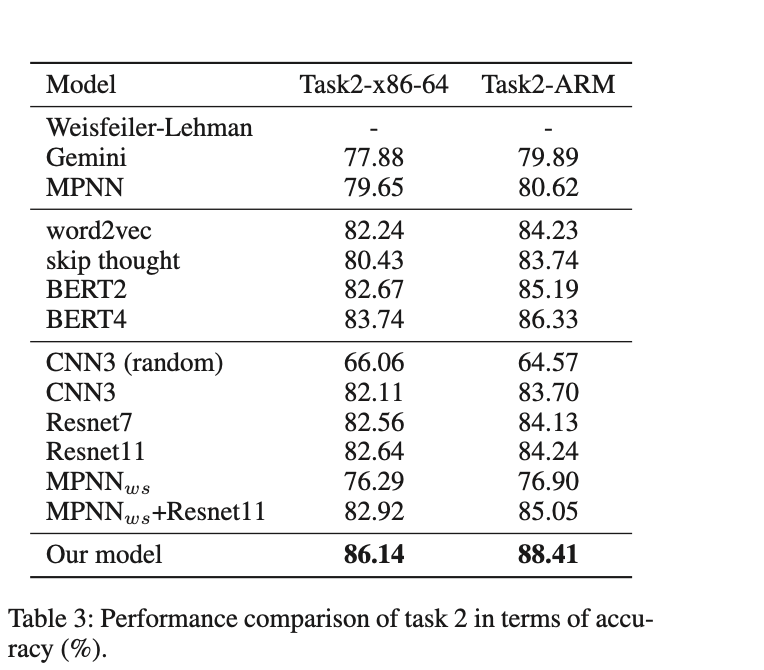
采用CNN确实能够学到控制流图中的节点顺序信息
Binaryai工具测试#
科恩实验室在github以IDA 插件的形式开源了上面的工作。具体安装参考手册即可,注意需要$IDA \geq 7.3$。由于需要批量化测试效果,所以简单实现了批量测试的脚本如下
1 | import sys |
测试结果是在这之前使用过的工具中结果最好的,具体表现在检出的数目最多,并且也保证了准确率,当设置阈值为默认0.9,选取top1结果时,测试的结果如下:
zlib 1.2.11 stripped
| 编译器 | 优化选项 | True | Wrong | 结果数目/函数总数 |
|---|---|---|---|---|
| Gcc | O0 | 112 | 10 | 122/218 |
| Gcc | O1 | 97 | 13 | 110/202 |
| Gcc | O2 | 94 | 13 | 107/196 |
| Gcc | O3 | 78 | 20 | 98/185 |
| Clang | O0 | 90 | 35 | 125/216 |
| Clang | O1 | 105 | 14 | 119/208 |
| Clang | O2 | 75 | 27 | 102/177 |
| Clang | O3 | 72 | 29 | 103/174 |
libpng 1.0.69 stripped
| 编译器 | 优化选项 | True | Wrong | 结果数目/函数总数 |
|---|---|---|---|---|
| Gcc | O0 | 224 | 64 | 288/570 |
| Gcc | O1 | 210 | 75 | 285/568 |
| Gcc | O2 | 209 | 74 | 283/572 |
| Gcc | O3 | 203 | 81 | 284/572 |
| Clang | O0 | 198 | 85 | 283/568 |
| Clang | O1 | 195 | 85 | 280/568 |
| Clang | O2 | 170 | 112 | 282/541 |
| Clang | O3 | 170 | 113 | 283/540 |
但工具也存在不足之处,尤其是对于小函数,由于缺乏足够的CFG信息,因此会出现一些误报,这应该也是插件代码中过滤了块数目不足3的函数的原因(idaapi.FlowChart(pfn).size < mgr.cfg['minsize']) 。

