CVE-2018-1336 An improper handing of overflow in the UTF-8 decoder with supplementary characters can lead to an infinite loop in the decoder causing a Denial of Service. Versions Affected: Apache Tomcat 9.0.0.M9 to 9.0.7, 8.5.0 to 8.5.30, 8.0.0.RC1 to 8.0.51, and 7.0.28 to 7.0.86.
漏洞原理 从补丁中可以看到问题出在函数decodeHasArray中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 --- a/java/org/apache/tomcat/util/buf/Utf8Decoder.java +++ b/java/org/apache/tomcat/util/buf/Utf8Decoder.java @@ -278 ,6 +278 ,11 @@ public class Utf8Decoder extends CharsetDecoder outRemaining--; } else { if (outRemaining < 2 ) { + + + inIndex -= 3 ; + in.position(inIndex - in.arrayOffset()); + out.position(outIndex - out.arrayOffset()); return CoderResult.OVERFLOW; } cArr[outIndex++] = (char ) ((jchar >> 0xA ) + 0xD7C0 );
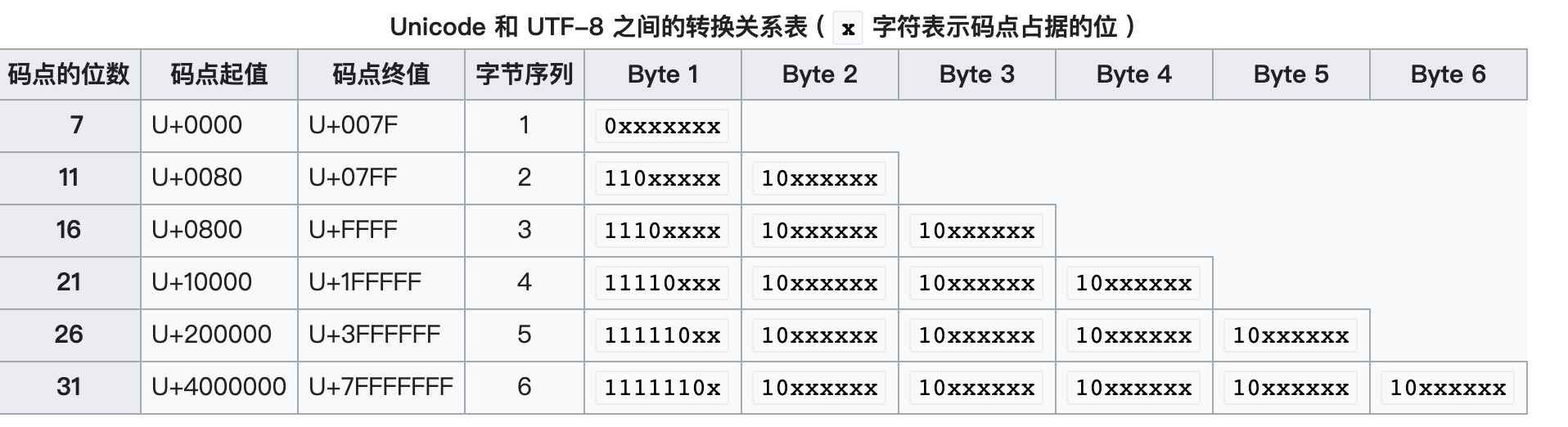
由于UTF8是可边长的编码方式,因此需要逐字节的判断是否符合UTF8标准,以及该编码的长度是几个字节
对于一个ByteBuffer类型,以下是我们需要关注的属性
position:当前的下标位置,表示进行下一个读写操作时的起始位置limit:结束标记下标,表示进行下一个读写操作时的(最大)结束位置capacity:该ByteBuffer容量remaining;该ByteBuffer当前的剩余可用长度为了防止缓冲区溢出,在decodeHasArray函数中对UTF8解码时,需要一直关注以上4个属性,尤其是解码后存放结果的Buffer的remaining属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 private CoderResult decodeHasArray (ByteBuffer in, CharBuffer out) int outRemaining = out.remaining(); int pos = in.position(); int limit = in.limit(); final byte [] bArr = in.array(); final char [] cArr = out.array(); final int inIndexLimit = limit + in.arrayOffset(); int inIndex = pos + in.arrayOffset(); int outIndex = out.position() + out.arrayOffset(); for (; inIndex < inIndexLimit && outRemaining > 0 ; inIndex++) { int jchar = bArr[inIndex]; if (jchar < 0 ) { jchar = jchar & 0x7F ; int tail = remainingBytes[jchar]; if (tail == -1 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } int tailAvailable = inIndexLimit - inIndex - 1 ; if (tailAvailable > 0 ) { if (jchar > 0x41 && jchar < 0x60 && (bArr[inIndex + 1 ] & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar == 0x60 && (bArr[inIndex + 1 ] & 0xE0 ) != 0xA0 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar > 0x60 && jchar < 0x6D && (bArr[inIndex + 1 ] & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar == 0x6D && (bArr[inIndex + 1 ] & 0xE0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar > 0x6D && jchar < 0x70 && (bArr[inIndex + 1 ] & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar == 0x70 && ((bArr[inIndex + 1 ] & 0xFF ) < 0x90 || (bArr[inIndex + 1 ] & 0xFF ) > 0xBF )) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar > 0x70 && jchar < 0x74 && (bArr[inIndex + 1 ] & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } if (jchar == 0x74 && (bArr[inIndex + 1 ] & 0xF0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } } if (tailAvailable > 1 && tail > 1 ) { if ((bArr[inIndex + 2 ] & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(2 ); } } if (tailAvailable > 2 && tail > 2 ) { if ((bArr[inIndex + 3 ] & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(3 ); } } if (tailAvailable < tail) { break ; } for (int i = 0 ; i < tail; i++) { int nextByte = bArr[inIndex + i + 1 ] & 0xFF ; if ((nextByte & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 + i); } jchar = (jchar << 6 ) + nextByte; } jchar -= remainingNumbers[tail]; if (jchar < lowerEncodingLimit[tail]) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 ); } inIndex += tail; } if (jchar >= 0xD800 && jchar <= 0xDFFF ) { return CoderResult.unmappableForLength(3 ); } if (jchar > 0x10FFFF ) { return CoderResult.unmappableForLength(4 ); } if (jchar <= 0xffff ) { cArr[outIndex++] = (char ) jchar; outRemaining--; } else { if (outRemaining < 2 ) { return CoderResult.OVERFLOW; } cArr[outIndex++] = (char ) ((jchar >> 0xA ) + 0xD7C0 ); cArr[outIndex++] = (char ) ((jchar & 0x3FF ) + 0xDC00 ); outRemaining -= 2 ; } } in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return (outRemaining == 0 && inIndex < inIndexLimit) ? CoderResult.OVERFLOW : CoderResult.UNDERFLOW; }
从UNICODE-UTF8转换表中可以看到,对于一个正常的UTF8编码,每个字节的首位都是1,因此在代码中使用int jchar = bArr[inIndex];得到的必然是负数,同时对标准的1 2 3 4字节长度的UTF8解码也会在判断if (jchar < 0)中完成,当然这个判断也并不是处理了所有的情况,当所有判断tail长度的if通过后,进入了下面decode的循环
1 2 3 4 5 6 7 8 9 10 for (int i = 0 ; i < tail; i++) { int nextByte = bArr[inIndex + i + 1 ] & 0xFF ; if ((nextByte & 0xC0 ) != 0x80 ) { in.position(inIndex - in.arrayOffset()); out.position(outIndex - out.arrayOffset()); return CoderResult.malformedForLength(1 + i); } jchar = (jchar << 6 ) + nextByte; } jchar -= remainingNumbers[tail];
最后得到的jchar就是UTF8解码后的值,最后在下面的判断中
1 2 3 4 5 6 7 8 9 10 11 if (jchar <= 0xffff ) { cArr[outIndex++] = (char ) jchar; outRemaining--; } else { if (outRemaining < 2 ) { return CoderResult.OVERFLOW; } cArr[outIndex++] = (char ) ((jchar >> 0xA ) + 0xD7C0 ); cArr[outIndex++] = (char ) ((jchar & 0x3FF ) + 0xDC00 ); outRemaining -= 2 ; }
jchar<=0xffff是UTF8编码为2字节的情况,而在jchar>0xffff时,其实就是编码为4字节的情况,当outRemaining < 2时,也就是说输出的Buffer不足以放入这个值了,而patch修补的问题就是,在不足以放入这个值的时候,将原来Buffer的index往前回退
**疑惑:**从commit描述和代码审计来看,都没有发现会造成CVE描述中所说的无限循环
参考 CVE-2018-8034 The host name verification when using TLS with the WebSocket client was missing. It is now enabled by default. Versions Affected: Apache Tomcat 9.0.0.M1 to 9.0.9, 8.5.0 to 8.5.31, 8.0.0.RC1 to 8.0.52, and 7.0.35 to 7.0.88.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @@ -328 ,7 +329 ,7 @@ public class WsWebSocketContainer implements WebSocketContainer , BackgroundProce // Regardless of whether a non -secure wrapper was created for a // proxy CONNECT , need to use TLS from this point on so wrap the // original AsynchronousSocketChannel - SSLEngine sslEngine = createSSLEngine(userProperties);+ SSLEngine sslEngine = createSSLEngine(userProperties, host, port); channel = new AsyncChannelWrapperSecure(socketChannel, sslEngine); } else if (channel == null ) { @@ -866 ,7 +867 ,7 @@ public class WsWebSocketContainer implements WebSocketContainer , BackgroundProce } - private SSLEngine createSSLEngine (Map <String ,Object > userProperties ) + private SSLEngine createSSLEngine (Map <String ,Object > userProperties , String host , int port ) throws DeploymentException { try { @@ -904 ,7 +905 ,7 @@ public class WsWebSocketContainer implements WebSocketContainer , BackgroundProce } } - SSLEngine engine = sslContext.createSSLEngine();+ SSLEngine engine = sslContext.createSSLEngine(host, port); String sslProtocolsValue = (String) userProperties.get(Constants.SSL_PROTOCOLS_PROPERTY); @@ -914 ,6 +915 ,14 @@ public class WsWebSocketContainer implements WebSocketContainer , BackgroundProce engine .setUseClientMode (true ) ;+ + + SSLParameters sslParams = engine.getSSLParameters(); + + sslParams.setEndpointIdentificationAlgorithm("HTTPS" ); + + engine.setSSLParameters(sslParams); + return engine; } catch (Exception e) { throw new DeploymentException(sm.getString(
加入了对host和port的验证,用的SSLEngine是java自带的SSLEngine类,在建立是加入了host和port信息后,后续的SSL连接都只能与该主机通信。防止在通讯建立后,后续通信被中间人劫持
参考