Detecting Code Clones with Graph Neural Network and Flow-Augmented Abstract Syntax Tree(SANER 2020)
基本介绍#
是一篇源代码和源代码相似性检测的论文,采用FA-AST构造图,然后使用图神经网络进行相似度计算
目前克隆检测主要分为这4种
- Type1:完全克隆,无修改
- Type2:重命名克隆,例如类型名,函数名,变量名等
- Type3:简单的增删等
- Type4:语义克隆
本文是一篇语义克隆检测的研究,实验对象为Java语言,但从方法上看,没有依赖于Java语言,感觉其他语言也可行,代码开源在github
贡献:
- 据我们所知,我们是第一个将图神经网络应用于代码克隆检测的研究, 我们采用两种不同类型的图神经网络并分析其性能之间的差异(但我感觉不是?)
- 提出了一种新的代码表示方式FA-AST,利用了控制流和数据流信息,基于AST构建
- 在测试集上表现优秀
图神经网络介绍#
对于图片来说,其实只有Pixel信息和全图/局部信息的区别。但是对于一张图(结构意义的图)来说,主要由节点信息(Node)、边信息(Edge),为了处理图,图神经网络就应运而生了,目的是将节点信息和边信息编码到最终的输出中,大部分图神经网络都可以用MPNN框架概括
MPNN:message passing neural networks
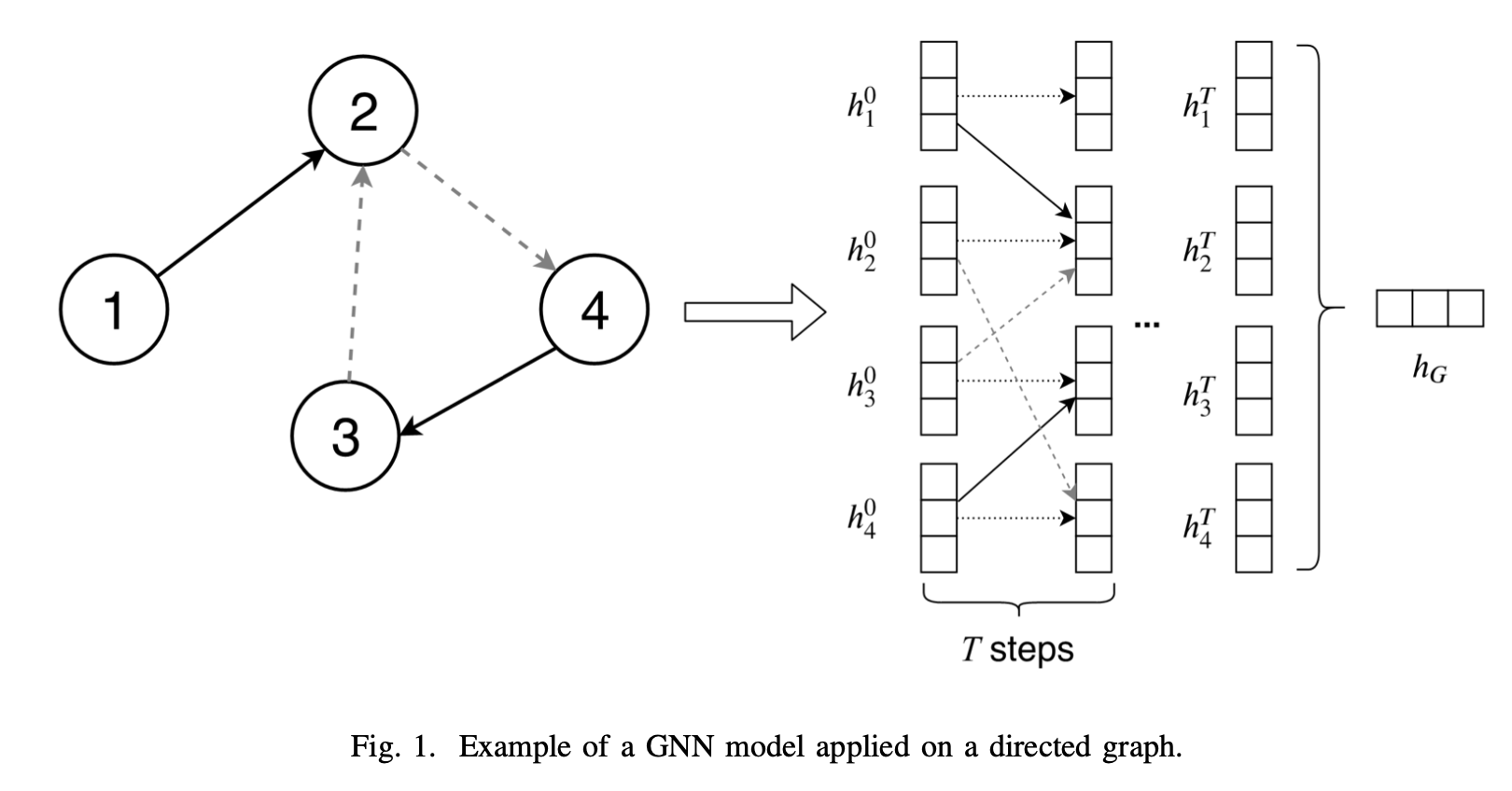
图:G(V,E),V是节点集合,E是边集合,每个节点包含隐藏状态h,每个边都有特征e
单个节点间信息传递(j -> i):

i获得的信息:
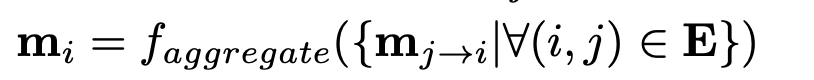
更新隐藏状态:

图编码结果(特征向量):
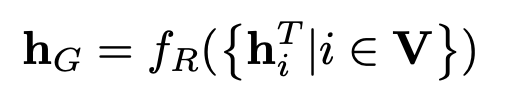
示例图如下:
方法介绍#
问题定义#
对于两个代码片段$C_i$和$C_j$,设置标签$y_{ij}$表示两者是否为克隆对
训练集:$D={(C_i,C_j,y_{ij})}$
训练一个模型,根据片段$C_i$和$C_j$生成相似性分数$s_{ij}$,相似性分数反应两者是否为克隆对
整体框架#

对于代码片段,先生成对应的AST,然后在AST的基础上加入边,构成图,最后使用图神经网络进行训练和检测,训练的Loss选择的是MSE(mean squared error)
FA-AST构造#
为什么选AST#
疑问: 为什么不使用Control Flow + 数据流而选择 AST + 数据流
理由:
- 控制流图的边没有抽象语法树多,对于图神经网络来说,更少的边意味着两个节点间的信息更少
- 在控制流图里大部分节点是语句,而不是token,如果对这些节点使用简单的算法比如Bag of words,会损失语义信息,另一个合理的方法是为每个语句构造子图,但是会耗费更多的计算资源
总体设计#
AST生成实现:使用python包javalang对java代码生成语法树
边类型:
- Parent:连接非终结节点到父节点
- Child:连接非终结节点到子节点
- NextSib:连接节点和它的相邻节点
- NextToken:连接终结符和终结符,体现next关系
- NextUse:连接当前使用和下次使用的节点
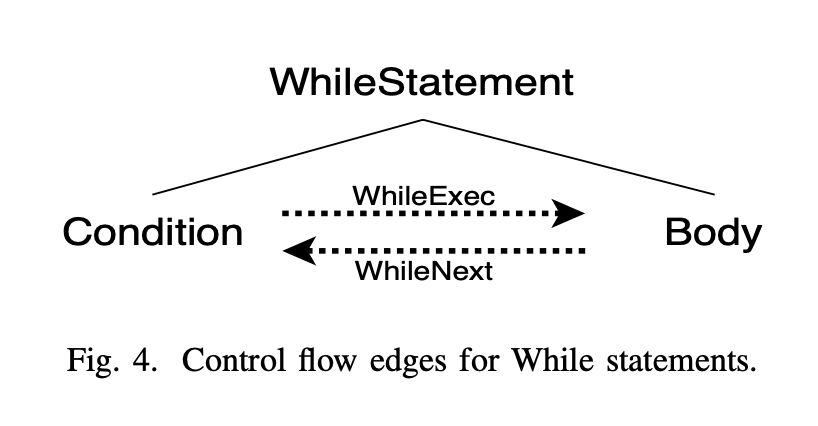
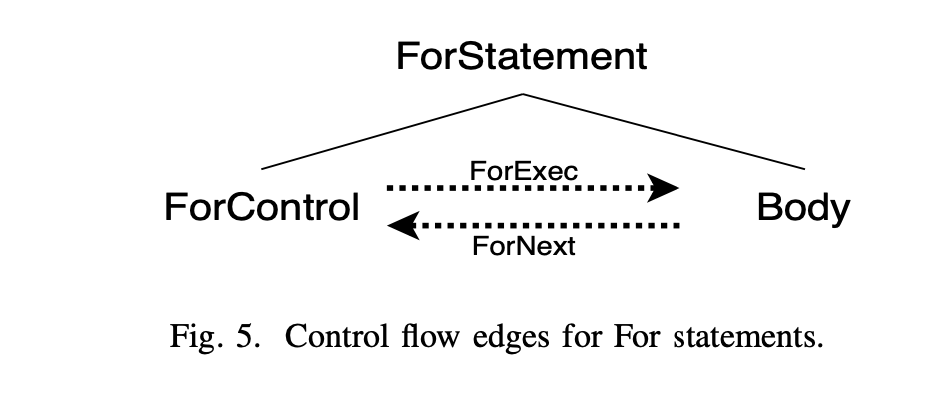
除了这些类型外,还为sequential execution, If statements, While and For loops这些类型加入了控制边
If语句#

While语句#
For语句#
Block代码块#

图神经网络#
两种方法:
- 使用GGNN计算Graph Embedding,然后计算相似度
- 直接使用GMN计算图相似度
在看的时候发现图神经网络这部分和一篇PRML 2019的思路不能说一模一样,只能说毫不相干(手动狗头),不过确实论文里写了参考的这个,Graph Matching Networks for Learning the Similarity of Graph Structured Objects。
GGNN#
具体可参考:https://zhuanlan.zhihu.com/p/83410937
好处是当存在大量数据时,只需要对Embedding后的数据进行相似度计算即可

GMN#
相对于GGNN,GMN能直接比较两个图,好处是可以重点比较图中的各个节点,牺牲计算复杂度获得精确度
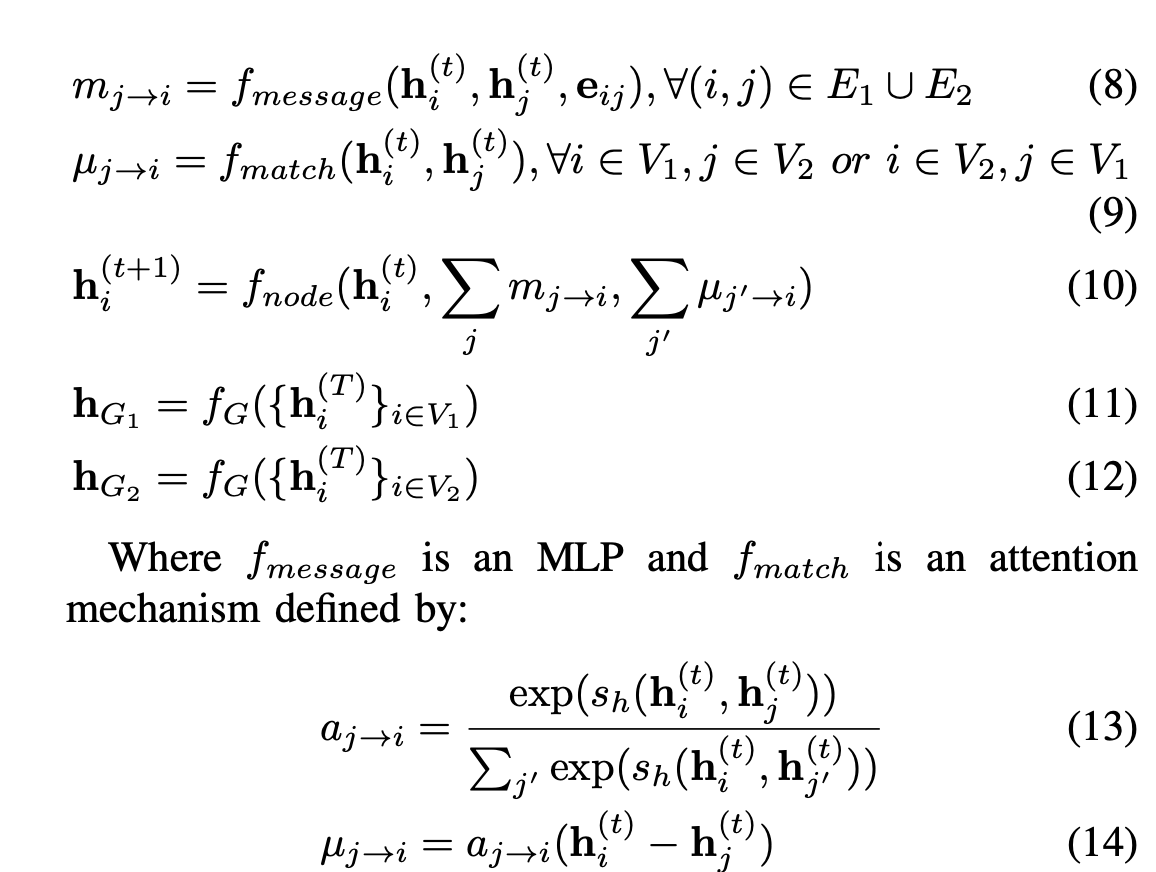
关键在于$u_{j\longrightarrow i}$,目的是去寻找两个图中的相似节点
实验#
数据集信息#
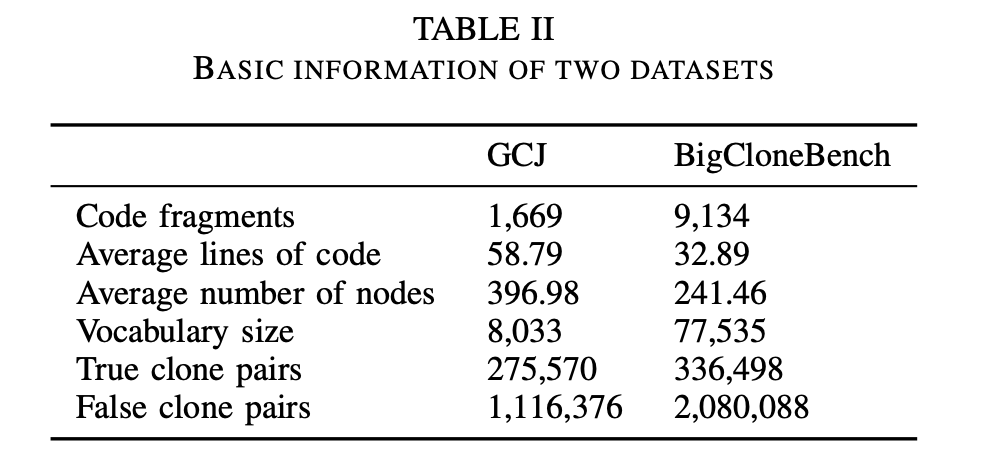
数据集:Google Code Jam (GCJ) and BigCloneBench
- Google Code Jam:是google举办的编程比赛,采用的数据包含1669个java文件和12个编程问题
- BigCloneBench :是一个代码克隆大型数据集,包含6000000个克隆对和260000个非克隆对
由于三型和四型界限问题,根据语句粒度的相似性划分如下:
- strongly type-3 (ST3):[0.7, 1.0),
- moderately type-3 (MT3) : [0.5, 0.7)
- weakly type-3/type-4 (WT3/T4) : [0.0, 0.5)
数据集基本信息:
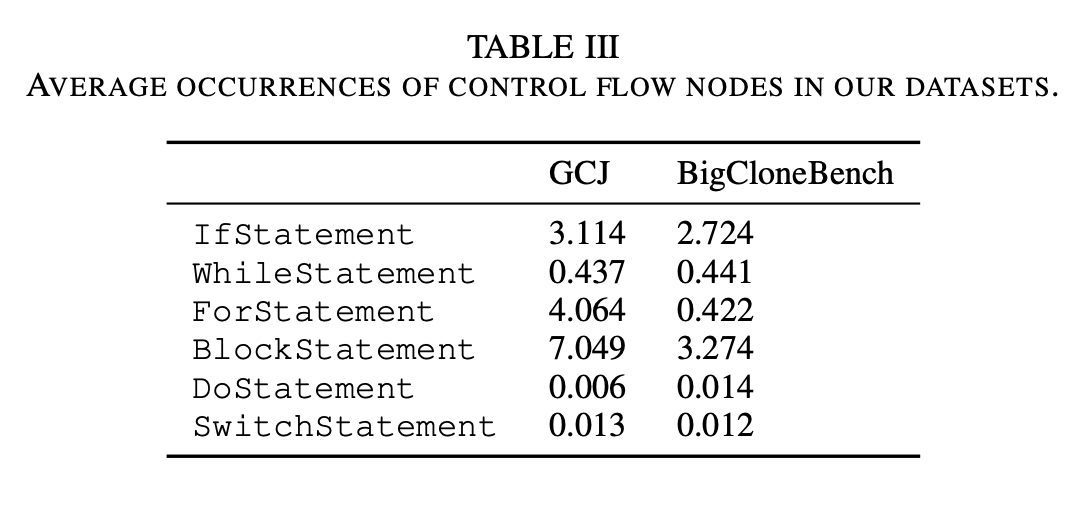
两个数据集中的控制信息:
实验设置#
和下列方法比较:
DECKARD:基于AST树的克隆检测,为每个子树生成vector,然后使用聚类算法检测克隆
RtvNN:RNN为token计算embedding,然后为AST计算embedding,计算相似性
CDLH:binary Tree-LSTM计算AST的embedding,计算相似性
ASTNN:RNN编码AST,然后计算相似性
数据集划分为8:1:1
实验结果#
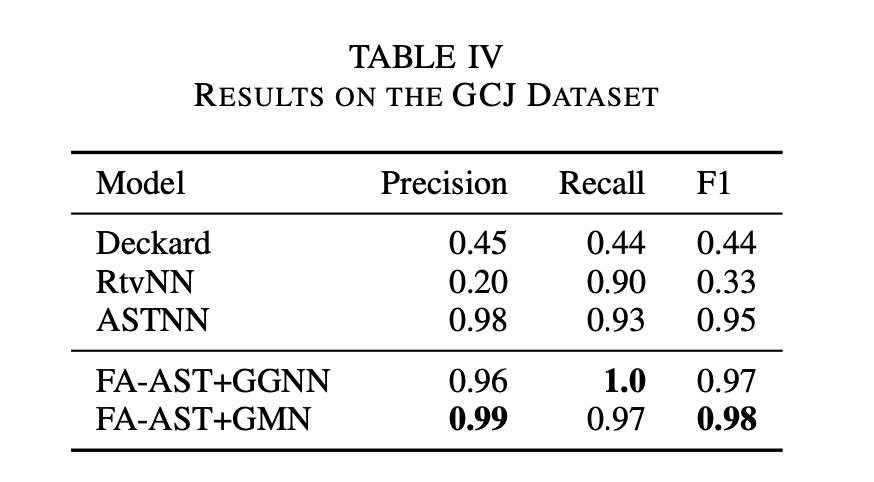
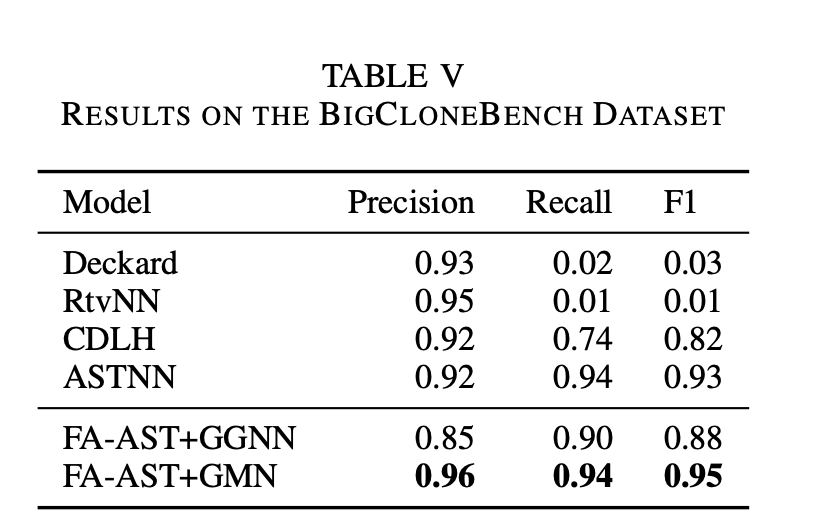
在两个数据集上的表现#
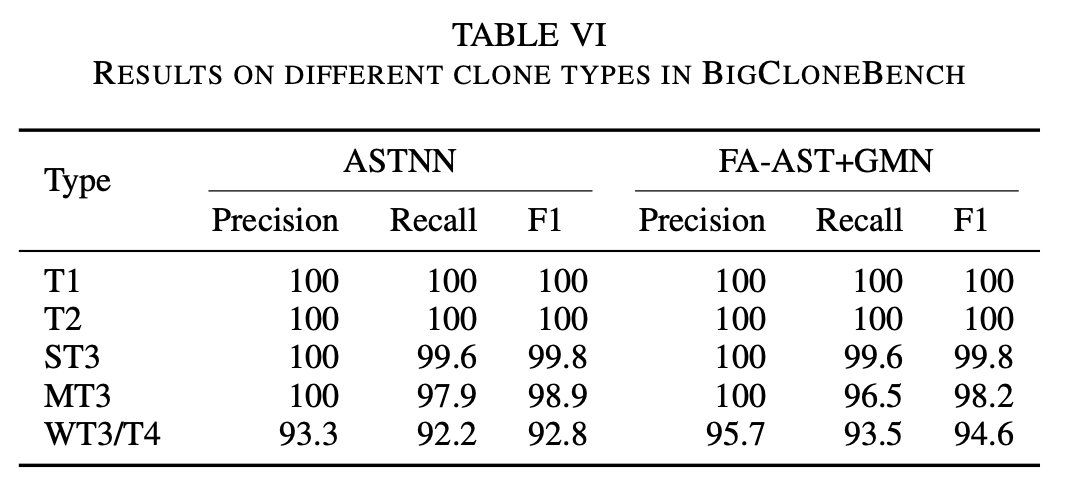
检测Type3/4克隆的能力#
讨论#
论文方法的优势:
- 综合了AST,CFG,DFG信息,而之前的方法没有那么全
- 将代码片段转换为图,作为信息输入,而之前的方法没有保留那么多的结构信息
- 检测到了一些ASTNN检测不到的克隆例子
示例1:ASTNN检测相似性为5.8e-7,FA-AST 0.94,功能上都是做了一个拷贝

示例2:ASTNN 相似性为0.94,FA-AST相似性为-0.27。a是文件解压,b是拷贝


