B2SFinder——Detecting Open-Source Software Reuse in COTS Software(ASE 2019)
B2SFinder: Detecting Open-Source Software Reuse in COTS Software#
B2SFinder 主要是为了解决闭源二进制软件中对复用开源组件检测的问题,由于复用了开源组件,当开源组件发现存在漏洞时,复用它的二进制软件也会存在漏洞,即OSS复用漏洞。
PS:我挂了个n作
Abstract#
虽然此前也有一些工作致力于研究二进制和源代码的匹配方法,并能进行大规模的分析,但他们只支持一些简单的特征。在他们的研究中只能近似的衡量OSS复用,忽略了项目中的代码结构。
为了解决这个问题,B2SFinder通过对二进制文件和源代码中的7种特征进行提取,并对7种特征使用三种匹配方法和两种重要性加权方法,计算匹配分数。通过这种方法,我们对1000个流行的二进制软件中的21991个二进制文件和2189个开源库的复用进行了评估。平均每个二进制文件耗时53.85秒。我们也讨论了如何使用B2SFinder检测OSS复用漏洞。
Introduction#
对于OSS复用检测,一般来说可以分为两种方法:
- 软件二进制 v.s. 开源组件二进制
- 软件二进制 v.s. 开源组件源码
对于第一种方法,主要存在以下两个问题:
- 从搜集到的2189个开源库中发现,只有1/4左右能自动编译
- 二进制相似性匹配效率低,难以规模化
对于第二种方法,此前也已有一些研究见下表

因此,我们能够提出以下问题:
- 选取哪些特征,且能对抗编译优化?
- 如何精确计算特征之间的相似性?
- 我们如何利用开源软件的代码结构来提高复用识别能力?
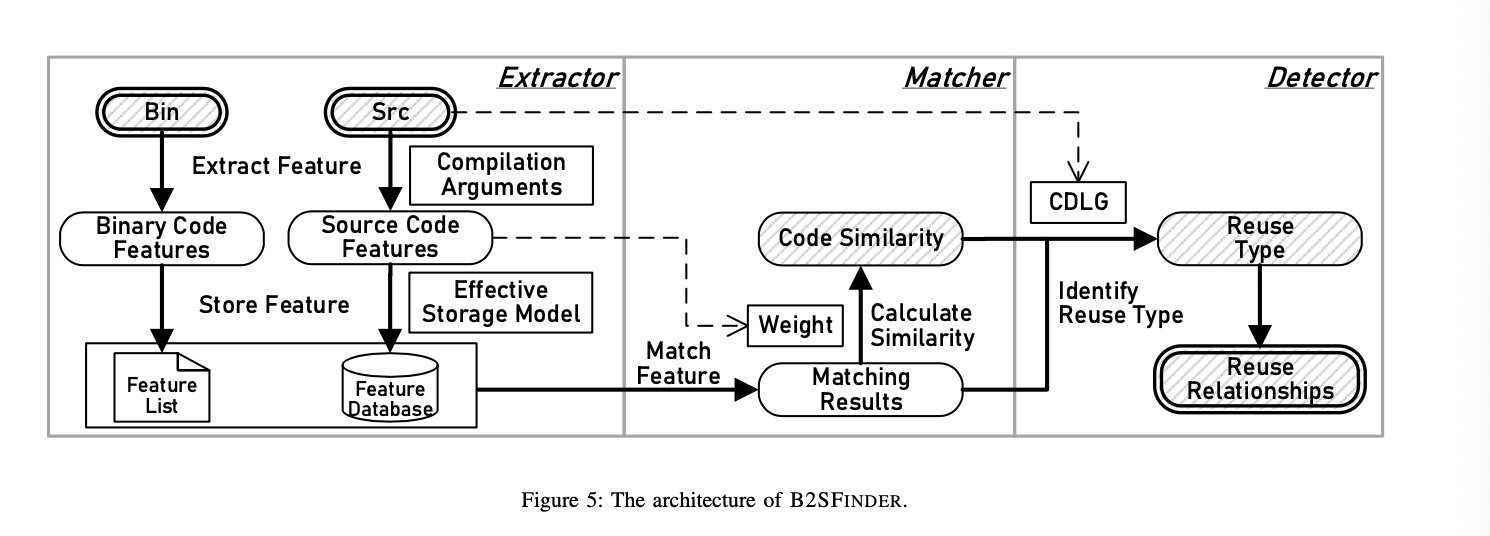
B2SFinder的工作流如下:
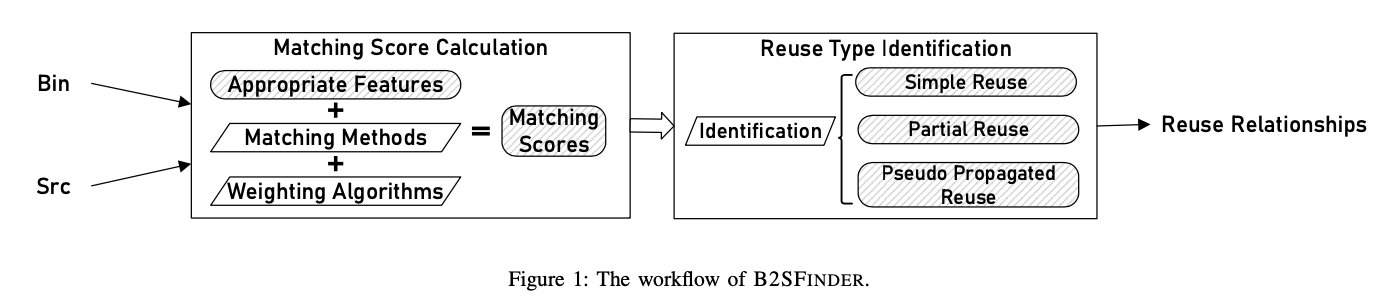
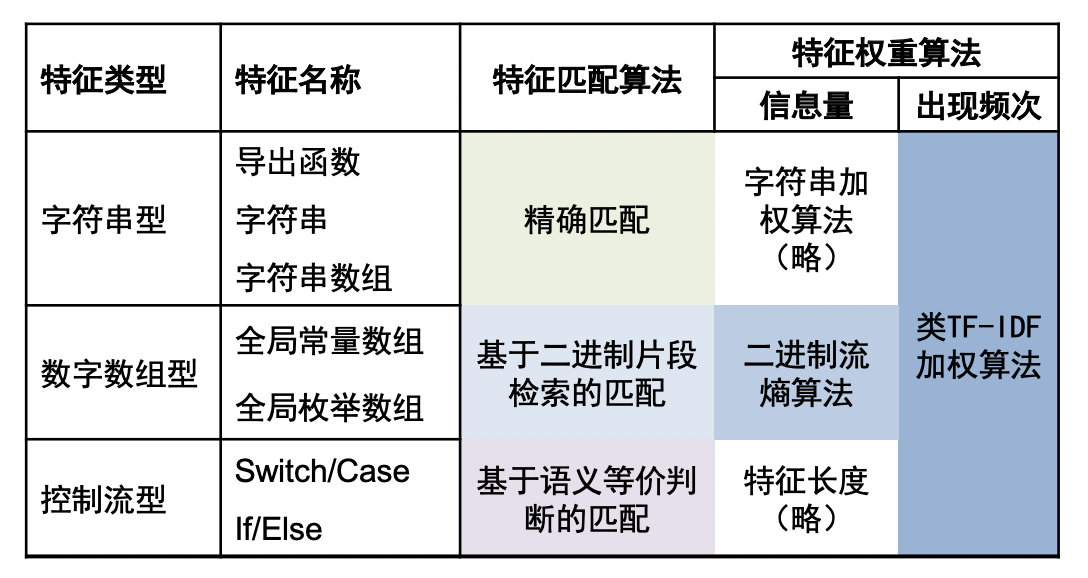
整体上的特征分类以及算法如下:
同时,我们也将复用分为以下三类:单一复用、部分复用和嵌套复用,其中前两类是真正的复用。
实验结果:
1000个闭源软件中的21991个二进制文件 v.s. 2189个开源库
达到了92.3%的检测精度以及88.5%的召回率,并且速度更快
在结果中发现63.4%的闭源软件复用了开源库,并且4.6%的开源库被复用了十次以上,平均每个库存在54.7个已知CVE。
Motivation#
以两个真实例子为例:
- Foxit Reader和ssleay32.dll复用openssl
- Libopenjp2-7.dll复用OpenJPEG
Matching Score Calculation#

从上图中可以看到,FoxitReader.exe和Openssl的export部分没有共同的函数名,并且只有19.7%的字符串常量为共有字符串。因此我们能够知道BAT和OSSPolice这两种方法在这一例子中效果是不理想的。但是我们能够在data段和rdata段以及text段找到一些其他的特征能够匹配上,最终,我们为B2SFinder选取了图中的7种特征。
有了特征,那么二进制和源码特征之间的特征匹配就是一个新的问题,特别是一些特征在编译的时候,会被轻微的修改
对于七种特征,我们共使用了3种特征匹配算法
- 字符串型(导出函数、字符串数组和导出函数):使用字符串之间的精确匹配并使用倒排索引方式检索。
- 数字数组型(全局常量数组、全局枚举数组):使用二进制片段检索的匹配
- 控制流型(if else、switch case):基于语义等价的匹配
注意匹配算法并不等同于匹配分数计算,对此,我们使用了两种分数计算方法
- 二进制信息熵
- TF-IDF
Reuse Type Identification#
分为单一复用和部分复用两类
在大多数情况下,匹配分数高判断为复用是正确的,这是最简单的一种,单一复用
实验中也发现了部分复用的情况,例如libssl(ssleay),只复用了openssl中7.6%的源代码文件,因此匹配分数并不高
为了识别部分复用的情况,考虑开源项目的代码结构是十分重要的。我们首先将开源项目分解为库模块,并分析编译过程获得库模块和源码的关系,例如openssl编译出来会有libssl和libcrypto两个库模块,称为开源库之间的包含关系。
Design#
Selecting Code Feature#
特征选取只要考虑两个影响:1、特征在源码和二进制上都存在;2、编译过程对特征改变不大。
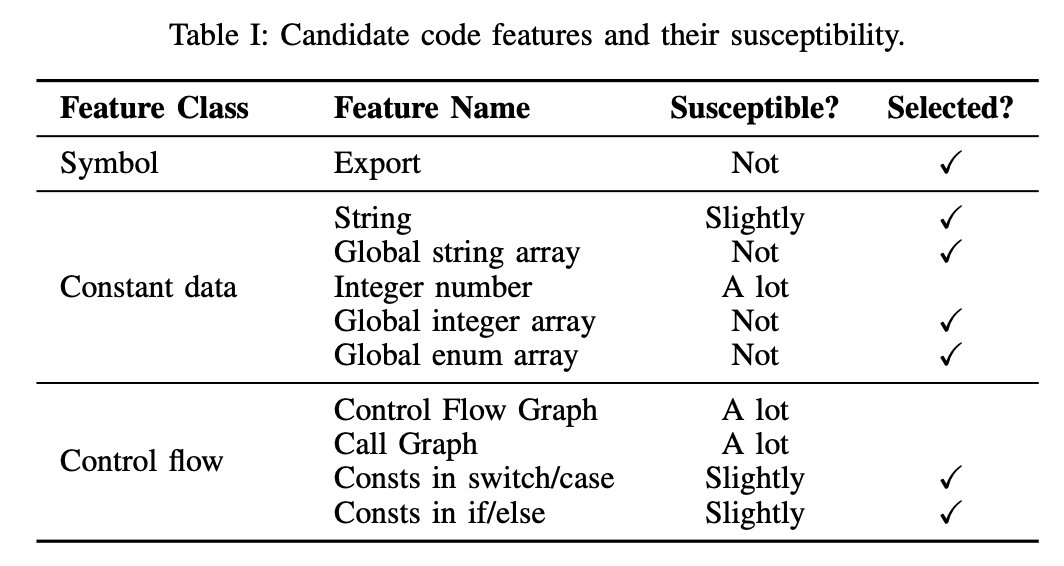
Matching Code Features#
将7种特征分为 字符串型、数字型和控制流型,并使用不同的算法进行匹配
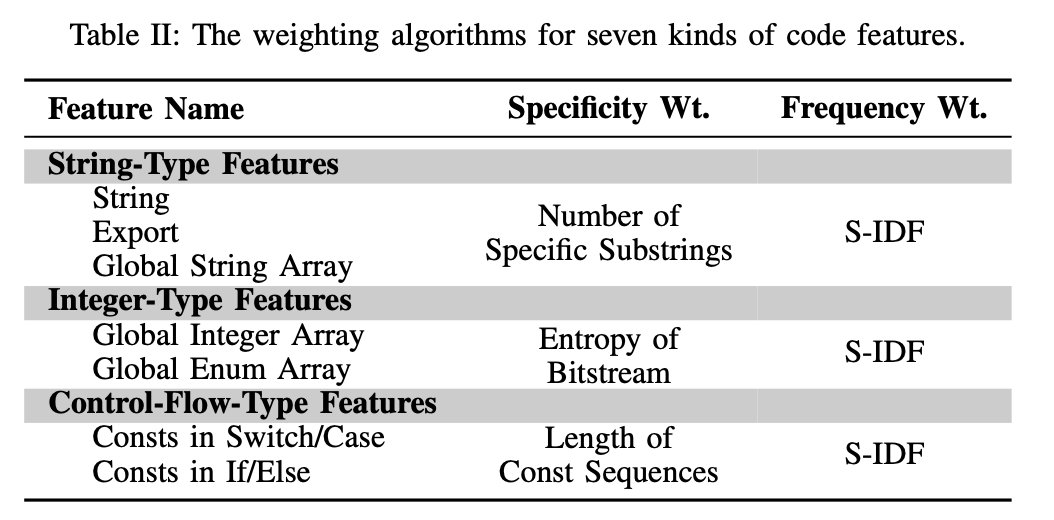
算法:
字符串型:完全匹配。
数字型:全局整数/枚举数组作为可搜索的连续比特流存储在二进制文件的数据段中,因此,采用将其编码后直接在.data和.radata中寻找的方法尽心匹配。
控制流型:基于语义的匹配。例如,对于switch case来说,源码中为[{0},{9},{16},{17},{20}],但二进制中提取到的jump table是{0},{9},{16},{17},{20},{1,2,3,4,5,6,7,8,10, 11,12,13,14,15,18,19},他们是语义等价的。对于if else特征来说,二进制提取的是最长的公共子序列[0x1,0x80,0x800,0x10000,0x200000,0x10],但源码中为[0x80,0x800,0x10000, 0x200000],他们也是匹配的,匹配长度为4
Determining the Importance-Weights of Feature Instances#
对于一些常见的特征,例如base64的表等,由于其特殊性不够,因此对判断复用哪个库的参考不够大,为了衡量特殊性,我们采用了类TF-IDF的S-IDF方法
For a string-typed feature, we use the number of its substrings, including URLs and copyright information (among others).
For an integer-typed feature, the entropy for its bitstream is used.
For a control-flow-typed feature, the length of its constant sequence is used.
Computing the Specificity Weights of Bitstreams as Entrophy

S-IDF for Computing Frequency Weights
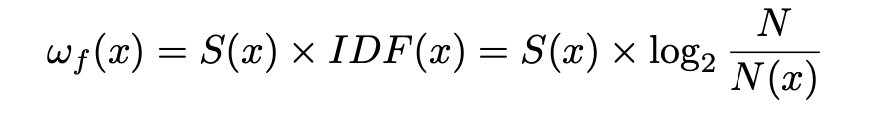
Computing Matching Scores#

Identifying Reuse Types#

识别部分复用:

识别递归复用:

IMPLEMENTATION#
个人感觉#
说一下在最近的分析和改进过程中,发现的一些尚需改进的问题:
在一些库中,由于存在大量static函数,一旦优化会产生内联,影响匹配效果。
在项目实现上,If else特征部分存在问题,由于比较的是cmp命令,因此在二进制特征提取时,循环中的判断常量也会提取出来,而源码仅提取if else中常量,虽然在比较时采用了最长匹配方法,但实际上仍不够理想。进一步改进可能得先识别循环,从二进制特征中将循环的cmp去除。

