FUZZIFICATION: Anti-Fuzzing Techniques(USENIX 2019)
fuzz作为一种自动化技术,在安全人员手中能够用来发现漏洞,但同时也让hacker能够通过fuzz寻找0day进行攻击。
为了解决这个问题,本文提出了FUZZIFICATION技术。在实际应用中,对外发布使用FUZZIFICATION处理过的二进制文件,提高hacker fuzz的难度和成本,而对内,由于安全人员拥有未处理过的二进制,使得安全人员能够在hacker fuzz出漏洞前更早的发现漏洞并进行修补。
Introduction#
anti-fuzzing的目的类似于二进制中的混淆技术,为了提高攻击者的攻击难度。攻击者虽然能够对FUZZIFICATION处理后的二进制文件进行fuzz,但需要耗费更多的经历(内存、算力、时间等)。而安全人员能够利用这个时间差在攻击者之前寻找漏洞并进行修补。
有效的anti-fuzzing技术应该满足以下三个条件:
- 能够有效阻止现有的fuzz工具,在固定时间内发现更少的错误
- 受保护的程序在正常状态下仍然能够正常运行
- 保护技术不应该被轻易识别并通过patch从程序中删除
现有的技术无法同时满足这三个目标:
- software obfuscation techniques:通过混淆阻止fuzz存在以下问题
- 混淆给正常执行带来很大的开销,例如ollvm混淆使执行速度降低了约25倍
- 混淆只能减慢单次fuzz的速度,但无法在路径上做文章
- software diversification:软件多样化能缓解攻击但无法隐藏根本漏洞
本文提出了三种FUZZIFICATION 技术,保护程序抵抗fuzz,分别是SpeedBump(注入delay),BrachTrap(插入jump)和AntiHybrid(阻止其他技术在fuzzing领域的应用),并实现了这三种防御机制。
为了评估FUZZIFICATION技术,作者在LAVA-M数据集和9个常用程序上做了实验,使用4个流行fuzzer(AFL、HonggFuzz、VUzzer和QSym)对受保护和未保护程序进行实验。
贡献:
- 阐明了anti-fuzzing方案的新研究方向。
- 提出并实现了三种有效的FUZZIFICATION方法。降低fuzzing速度,隐藏路径覆盖范围、阻止动态污点分析和符号执行。
- 使用流行的fuzzer和通用基准进行评估。从真实二进制文件中发现的bug减少了93%,从LAVA-M数据集中发现的bug减少了67.5%,在保持用户指定的开销预算的同时,覆盖率也降低了70.3%。且数据流和控制流分析技术无法轻易移除FUZZIFICATION技术。 源代码:https://github.com/sslab-gatech/fuzzification
Background and Problem#
Fuzzing techniques#
为了在fuzz的时候速度更快,一般会从加速单次执行的速度或者减少执行的次数考虑
- 单次执行加速:定制的硬件、并行fuzzing
- 覆盖率:收集每次执行的代码覆盖率,并优先fuzz触发新分支的输入。一般采用基本块或者分支来统计代码覆盖率
- 启发式:使用污点分析等方法帮助fuzz
FUZZIFICATION Problem#
问题场景:
程序开发人员希望由自己或者受信方公开漏洞,而不是黑客,而Anti-Fuzzing技术能够阻碍恶意人员的fuzzing,实现这一目标
FUZZIFICATION流程:
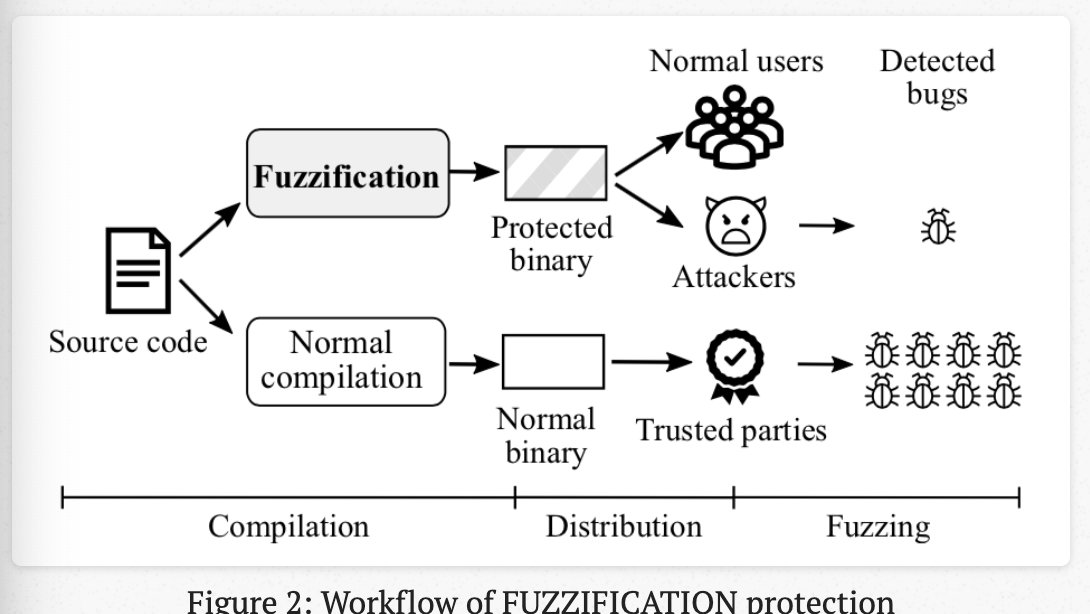
- 对外公开使用FUZZIFICATION技术编译生成受保护的二进制文件
- 对内使用常规方法编译生成正常的二进制文件
- 通过两者fuzz的差距,完成目标
攻击方设定:
- 有限的资源
- 只有受FUZZIFICATION保护的二进制文件
FUZZIFICATION技术目标:
- **Effective:**与原始二进制相比,能够在同样的资源条件下,有效减少发现的bug数量
- **Generic:**对大多数fuzzer适用
- **Efficient:**对常规适用影响小
- **Robust:**能够抵抗试图从二进制文件中删除保护的方法
下列已有的方法都无法同时满足这四个要求

Design Overview#
针对上述分析,本文提出了三种FUZZIFICATION技术:
- **SpeedBump:**在二进制中插入延迟原语,在fuzz时会频繁使用,而正常时不怎么使用
- **BranchTrap:**构造对输入敏感的分支,使得基于覆盖率的fuzzer多走弯路,同时有意使得频繁路径冲突,从而达到让fuzzer无法识别触发新路径的输入
- **AntiHybird:**将显式数据流转换为隐式数据流,防止通过污点分析进行数据流跟踪,插入大量伪造符号在符号执行过程中触发路径爆炸
SpeedBump#
**原理:**fuzzer在进行fuzz的时候,会进入类如错误处理的路径,而在正常使用时这些路径并不会经常被执行。所以在这些cold path中注入延迟原语,可以大大降低fuzz执行的速度,且不会对正常执行产生大影响。
方法:
- 正常编译二进制文件,对二进制文件进行测试,找到cold path
- 通过生成基本块的频率曲线,识别cold path
- 确认注入延迟的cold path数目和延迟大小,使正常执行时开销在预算之内
- 重复操作,调整延迟大小
如果简单的注入sleep等语句,那么可以十分方便的进行去除,所以作者设计了基于CSmith的原语,使用算数运算并和原始代码关联

BranchTrap#
**原理:**对于使用覆盖率的fuzzer,通过插入大量对输入敏感的分支,使得fuzzer陷入对这些分支的分析中,误导fuzzer
构造大量条件分支和间接跳转,这些条件分支与输入的字节相关,因此对输入敏感。
为了使fuzzer关注假分支,作者考虑了以下四个方面
- 假分支足够多
- 注入的分支和路径对常规运行带来的开销影响小
- 路径需要与输入相关
- 无法被攻击者轻易去除
方法:
- CFG Distortion: 注入跳转表,使用输入作为索引,并且使用类似于ROP的方法,使用gadget
- 优点1:与输入相关联,所以fuzzer不会忽略这些分支
- 优点2:轻量级的解析跳转对正常情况下影响小
- 优点3:基于ROP方法,增加了去除的难度
- **Saturating Fuzzing State:**使fuzzing状态饱和,在很少访问的分支中加入大量确定性分支
AntiHybird#
原理: 模糊测试的弱点
- 符号执行和污点分析需要大量资源
- 符号执行容易受到路径爆炸的问题
- 污点分析难以跟踪隐式的数据依赖
方法:
将显示数据流转换为隐式数据流,对抗污点分析
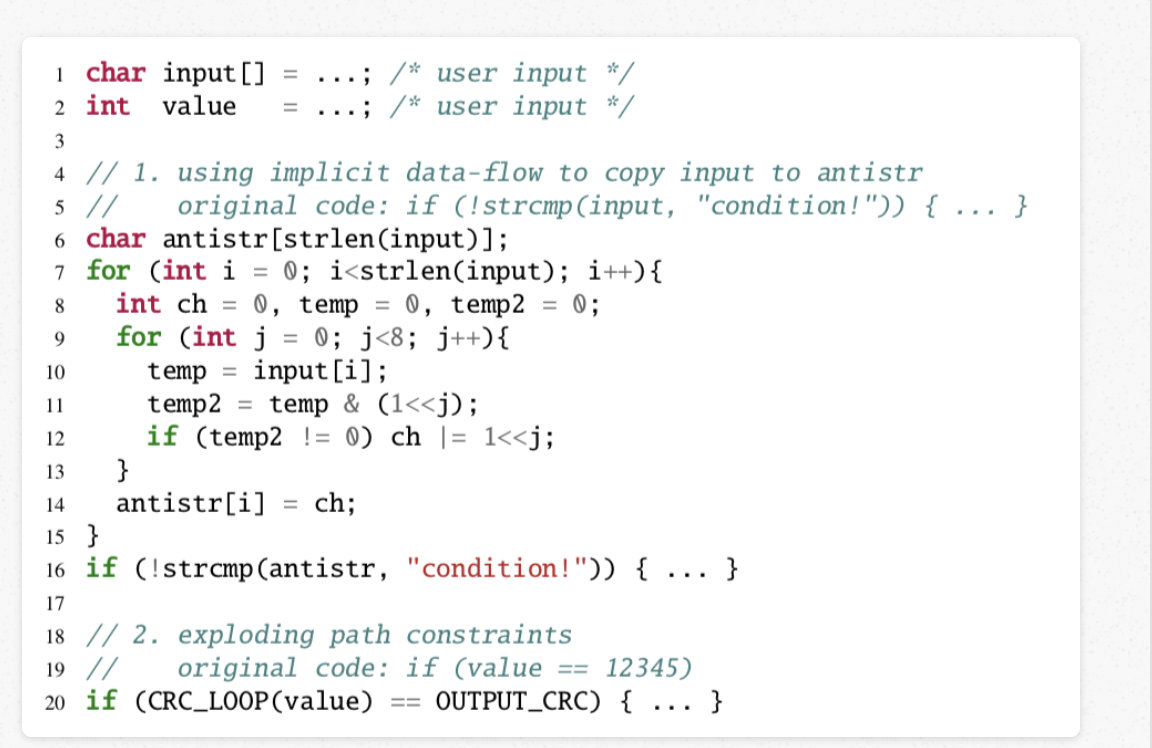
注入多个代码块,有意触发路径爆炸,对抗符号执行
Evaluation#
都在论文里,效果可以说是十分不错
个人看法#
论文中提出的三种方法都是针对于当前fuzzer的策略和原理一一提出的方案,短时间内应该很难有更好更全面的的Idea产生了,被UNSNIX接收也是实至名归。
可以说FUZZIFICATION打开了一个新的研究领域。同时对比于二进制中的混淆和反混淆,可以预见到:如果FUZZIFICATION持续受到研究人员关注的话,那么DE FUZZIFICATION 也会成为研究或者实践中的热点问题之一。
例如可以想策略去除FUZZFICATION的设置,或者在fuzzer中加入新的启发式策略,从而减少FUZZIFICATION对fuzzer的影响。

