LEOPARD: Identifying Vulnerable Code for Vulnerability Assessment through Program Metrics(ICSE 2019)
识别代码中的脆弱点漏洞评估的重要步骤,当前主要的两种方法为:基于度量和基于模式。前者基于机器学习,后者依赖先验知识。本文提出并实现了一个通用、轻量且具有可扩展性的基于程序指标识别漏洞函数的框架 LEOPARD,这个框架不需要任何漏洞的先验知识就能识别脆弱点。第一步,通过复杂的程序指标将目标应用的函数分类;第二步,对每个分类中的函数进行排序,并将排位靠前的函数作为漏洞函数。在实际应用中,LEOPARD将20%的函数中识别出了74%的漏洞函数,从PHP,r2等应用中找到了22个新bug,其中8个是新漏洞。
Introduction#
两种方法:
- Metric-based:
- 使用监督学习或无监督学习,在文件粒度级别预测漏洞
- 缺点:复杂度过高,需要采用复杂的特征,例如词频,依赖关系等
- Pattern-based:
- Pattern来自于语法或语义抽象,基于先验知识
- 检测特定类型的漏洞,例如missing check等
存在的问题:都基于先验知识,复杂度太高等
LEOPARD:
- 用于漏洞评估,而不是指出漏洞在哪里(???我感觉挺扯淡的这个东西)
- 不需要先验知识,使用complexity metrics和vulnerability metrics
- complexity metrics:关注函数复杂性(循环复杂性和循环结构)
- vulnerability metrics:关注函数依赖、指针使用,控制结构的依赖关系
分为两步:
- 第一步:使用complexity metrics将函数分为多类
- 第二步:使用vulnerability metrics对每一类中的函数进行排序,靠前者为可能的漏洞函数
Methodolody#
整体框架如下图:
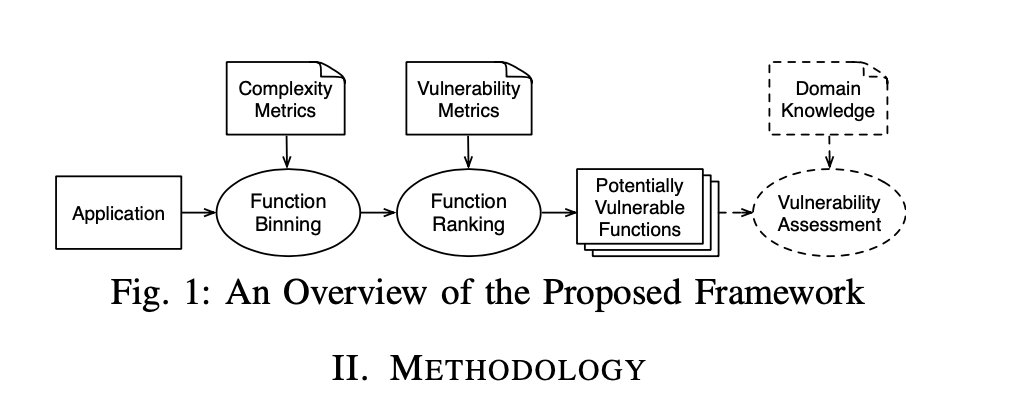
Function Binning#
不同的漏洞通常具有不同的复杂程度。为了识别各种复杂程度的漏洞,首先将目标应用程序中的所有函数基于复杂度分为多个种类。每个种类代表不同的复杂程度,供后面的Function Ranking来做预测。这种分级和排序方法旨在避免遗漏低复杂性的易受攻击的功能。
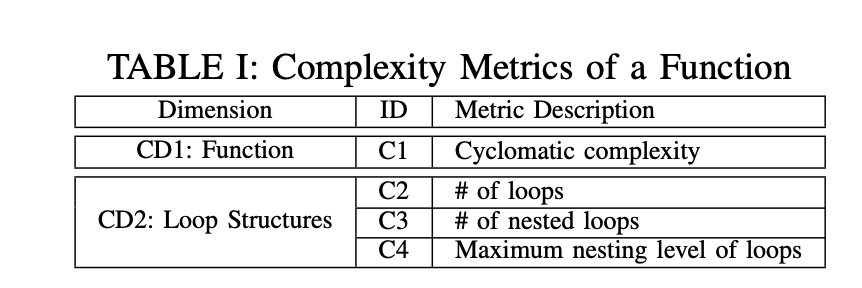
两类特征:
CD1:主要考虑函数中的路径数目
CD2:主要考虑循环结构的特征,包括循环数、嵌套循环数和循环的最大嵌套级别。
Function Ranking#
根据漏洞的一般特征推导出一组新的漏洞度量,然后对每类中的函数基于度量进行排序,将最上层函数识别为易受攻击的函数。

主要选用选用了三类特征:
- 依赖度量:包括函数参数已经caller和callee之间的依赖
- 指针度量:指针算数运算的数量、指针运算中涉及到的变量数目等
- 控制流结构度量:最大控制流依赖等
Applications of LEOPARD#
由于之前说过LEOPARD不是直接检测漏洞,只是用来预测哪部分很可能出现漏洞,因此这里讲的是对LEPPARD的应用。
主要是拿LEOPARD的结果去fuzzing,然后发现了22个bug,其中8个是漏洞。
Evalutaion#
主要针对以下五个问题进行评估
Q1. Is the binning step before the ranking step reasonable?
Q2. Is our binning-and-ranking approach effective, and can it outperform baseline approaches, machine learning-based techniques and some off-the-shelf static scanners?
Q3. What is the sensitivity of the metrics to the effectiveness of our framework?
Q4. What is the performance overhead (i.e., scalability) of our framework?
Q5. What are the potential application scenarios of LEOP- ARD?
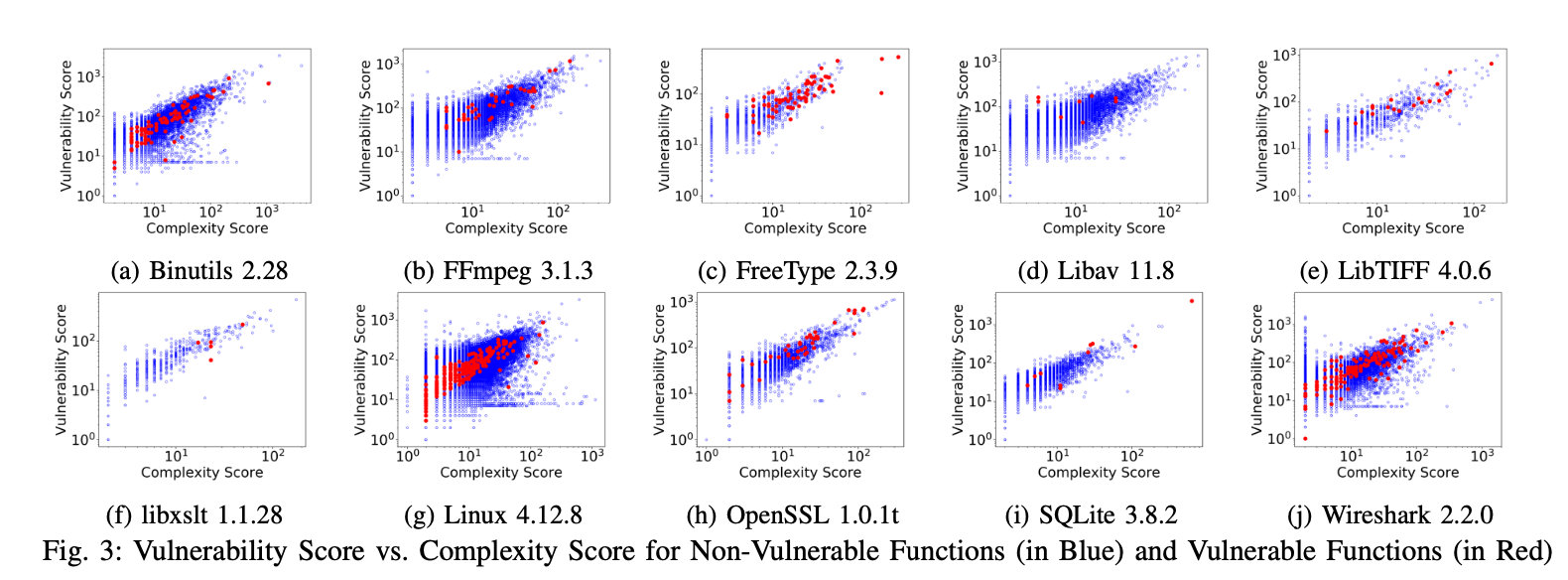
Q1:
通过在现有的ground truth中使用度量计算分数,可以看到其中确实存在着关系
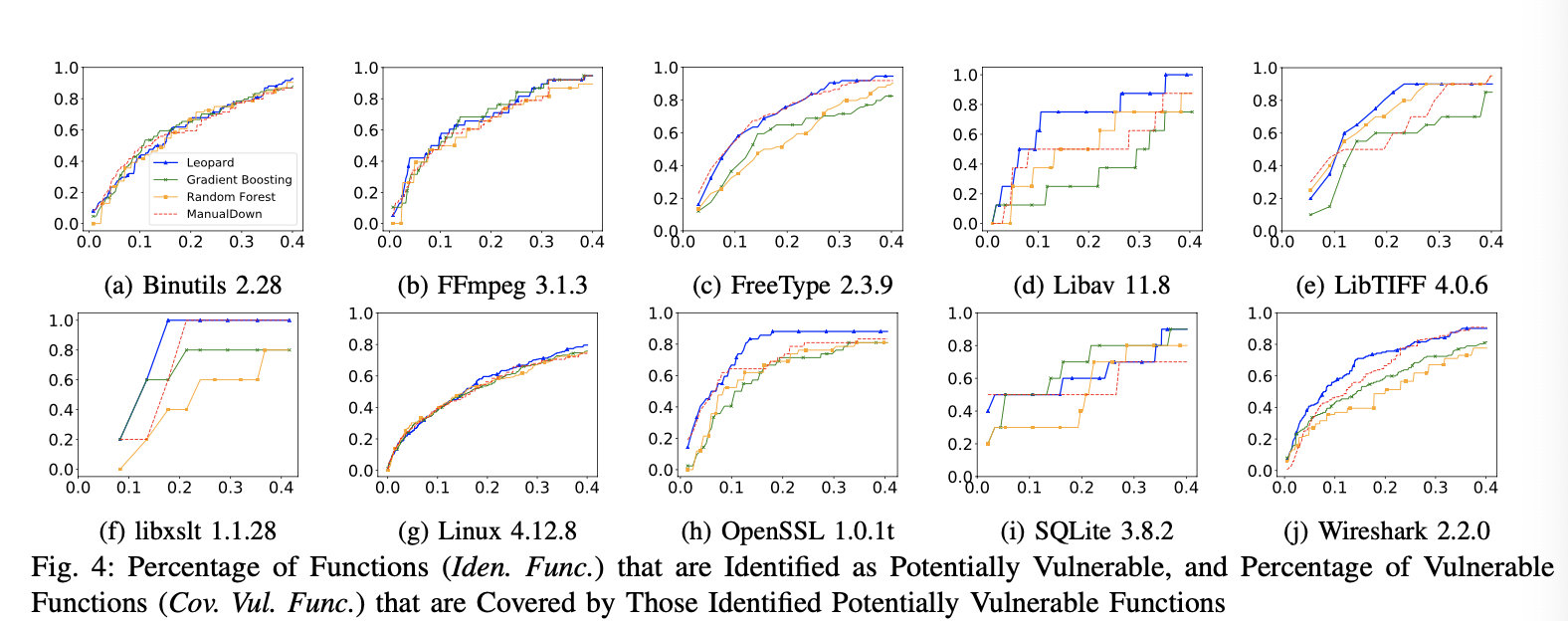
Q2:
通过和现有的方法对比,主要评估相同百分比的源代码中找到的漏洞占比
Q3: 通过在原来的度量上去掉某度量和不去掉时的效果进行比较,结论为,去掉后的效果都不如去掉前,每个度量比较敏感,所以总体度量的选择是比较合适的
Q4:经过在大项目中的评测,可以适用于大规模处理
Q5:主要应用前景还是在进一步的fuzz中,LEOPARD的结果对灰盒fuzz帮助较大
个人感觉#
总体来说,启发式的方法对于分析人员还是很有好处的,分析人员能重点关注启发式的结果,在同样的投入下得到更高的审计产出。
之前关注的都是直接找漏洞的研究,但确实都需要先验的知识,例如基于0day的patch找1day等。文中方法虽然也是有先验的信息,但不需要大量的数据收集和训练等步骤,可以说是一种通用的启发式方法。
整体感觉上,是阐述了 越复杂的函数越容易出漏洞的 简明道理。

