NTFUZZ: Enabling Type-Aware Kernel Fuzzing on Windows with Static Binary Analysis(S&P 2021)
基本信息#
研究重点:基于二进制文件静态分析,推断Nt系统调用的参数类型,然后对Nt系统调用进行Fuzz
研究背景:之前的一些kernel fuzz大致可以分为两种,1. 对windows kernel的一部分进行fuzz(font 组件等);2.通过IOCTL接口对驱动进行fuzz
除了NtCall(工具)外还没有对系统调用进行fuzz的研究,而且NtCall的fuzz并未对系统调用参数的类型进行推断
问题来源:
- 目前对windows的fuzz大多是对上层应用的fuzz,通过fuzz上层应用来找漏洞,有时确实可以找到windows kernel的漏洞
- 直接对系统调用进行fuzz,如果不知道参数类型的话,很多都是无效的fuzz,而我们能找到的文档化的系统调用只占了一小部分
解决方案:
- 基于二进制文件静态分析,推断系统调用的参数类型
- 使用推断后的系统调用参数类型,在应用运行时产生的上下文中对系统调用进行fuzz
知识补充#
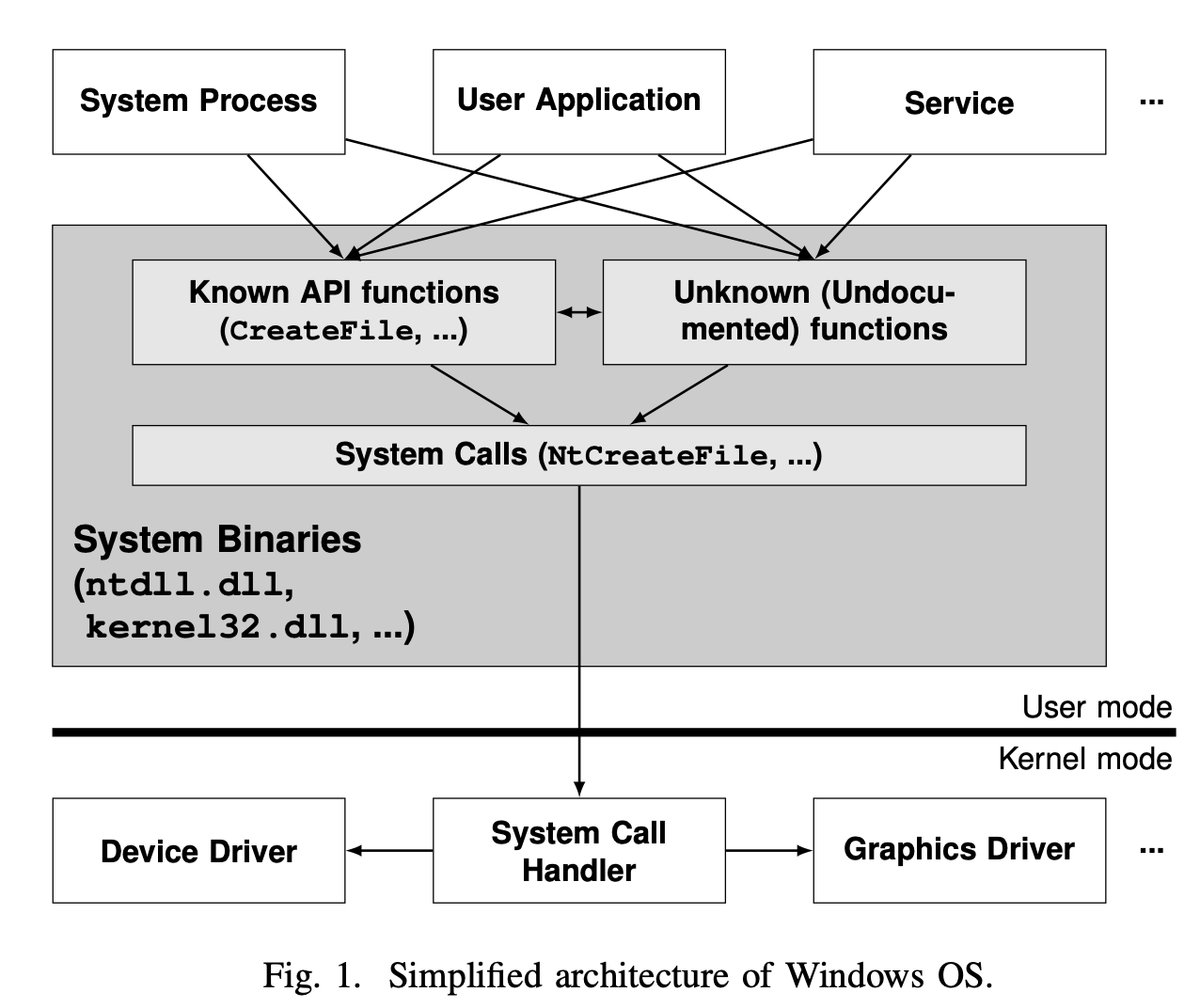
目前windows的架构大概如上
在上层运行着系统进程,用户应用,系统服务,它们使用windows提供的一些API(文档化的/未文档化的),通过系统自带的dll中封装的系统调用执行kernel提供的服务
在windows中大部分的API是没有文档化的,只有一部分的API使用可以在文档中找到,这些API在windows自带的dll中(aka system binaries)可以找到实现,这些dll中封装了大部分对系统调用的使用,目前windows大概有1600多个系统调用。
本研究通过静态分析这些system binaries,来推断系统调用所使用的参数,目前选取的这些dll中,包含了大概80%的系统调用

一个示例#

系统调用NtUserRegisterWindowMessage使用UNICODE_STRING*作为参数
BUG描述:LINE 11检查了数据所在段是否正常,但是当LINE 6判断正确时,并不会进行这个检查
结论:
如果我们不知道
NtUserRegisterWindowMessage的参数类型,那么我们很难对系统调用进行fuzz,fuzzer需要知道参数是一个指针,且指向了UNICODE_STRING结构,不满足该结构的话其实话很多判断都绕不过去未文档化的系统调用常常与文档化的API相关,比如从API
RegisterWindowMessage中其实可以看出来,str是一个UNICODE_STRING结构指针,且它的参数有一个字符数组和一个标志长度的成员对API进行fuzz存在一定的问题,如果只对API进行fuzz的话,
UNICODE_STRING是在API内构造出的结果,永远不会触发上面所述的BUG
NTFUZZ#
架构#
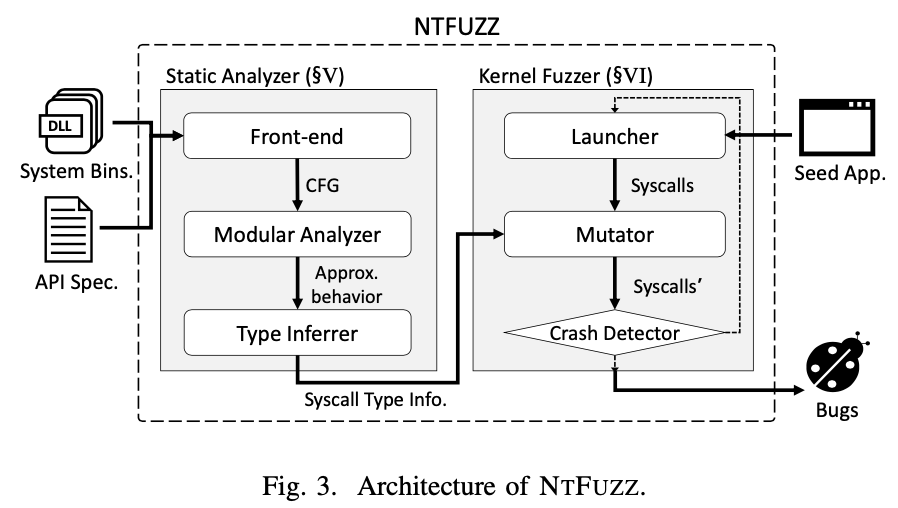
两部分:
- 静态分析器接收二进制文件和API文档,对系统调用的参数类型进行推断
- 动态fuzz运行种子app,动态更改系统调用中的参数
静态分析模块
- 前端:将二进制文件转换为IR,生成CFG;解析API文档,转化为适应于分析的格式
- 模块分析:接收输入,观察API输入如何影响系统调用的参数
- 类型推断:根据模块分析结果推测参数类型
内核Fuzzer模块
- 启动器:准备hook系统调用和种子app
- Mutator:在app执行过程中修改系统调用的参数
- Crash检查器:确认是否为内核漏洞,生成报告
模块化分析#
将一个程序分为多个模块进行分析,然后汇总分析结果
NTFuzz的分析采用自下而上分析的方法,对下层函数分析结果生成摘要,然后再分析上层函数

输入控制流图,函数调用图和API文档解析的结果,从函数调用图逆序访问的叶子节点进行遍历,推测参数类型
这种模块化分析的结果大大提高了分析的效率(相对于直接分析整个二进制文件),同时也是过程间相关、上下文相关的
但是也有一定问题,例如无法处理间接调用和递归调用
模块化分析示例#

示例以c语言展示,但其实上分析器是在二进制上进行分析的,因此示例中隐去了g和h的参数类型
- 先遍历找一下逆访问序列
h -> g -> f或者g- > h -> f,假设选用h -> g -> f访问序列进行分析 - 首先分析h,可以得到a是一个指针,指向了b所在的空间
- 然后分析g,可以得到系统调用的第一个参数是一个整数,第二个参数对应g的参数
- 最后分析f,可以知道大小为8字节,第一个成员为x,是HANDLE类型,第二个成员是10,为INT类型
- 最后可以推断出y的类型如右图所示
挑战#
- 二进制分析时要跟踪跨函数的数据流,例如在示例中,应该知道f到g的数据流,同时需要理解g中的参数来自于第三行的p
- 需要跟踪内存状态,分析器应该知道如何分配p,并且在函数h中设置具体内容
静态分析模块#
前端#
前端主要负责解析二进制文件和windows api文档
二进制解析
B2R2:将二进制文件转换为IR表示,这种IR只用一些基本操作就可以描述二进制的语义,如下,然后根据jump等语句建立函数的CFG,最后再根据call语句建立函数调用图

为了减小调用图的大小,首先找到系统调用,然后标识存在系统调用的函数为系统调用根函数(直接调用系统调用的函数),然后从这些函数反向遍历调用图直到找到api文档化的函数,这些访问到的函数集合标为S1
然后从S1集合出发,找到所有能遍历到的函数集合,标为S2,最后分析的时候只分析S1和S2的合集
文档解析
从windows SDK中找函数声明,获取类型信息,同时也从SAL描述中找信息
模块化分析#
抽象域#
为每个函数进行流敏感的分析,为每个点生成程序状态,根据这些状态,分析哪些值与系统调用有关,以及这些值在入口点到出口点的变化来为每个函数做总结

分析中用到的抽象域规则如上,Z表示整数域,symbol是函数每个参数所引入的新符号
V是三元组集合,包括值,位置和类型约束
整数抽象:由寄存器/内存的初始值线性变换而来
位置抽象:表示一个值可能存储的位置
- Global(a)表示是变量a的值
- Stack(f,o)表示存在于函数f栈上偏移o的位置
- Heap(a,o)表示存在于堆上结构a,偏移为o的位置
- SymLoc(s,o)表示存在于一个符号化指针偏移为o的位置
最后推断结束后,一个类型约束可以是具体的类型或者是一个符号化的类型
示例
假设一个函数只有一个参数(整数或者指针)
先假设是整数,那么参数符号化为$1 ∗ α_1 + 0$,同时符号化位置为$SymLoc(α_2,0)$,由于还不知道类型的约束是什么,所以符号化为
$SymTyp(α_3)$,最后生成V为$⟨α_1, {SymLoc(α_2, 0)}, {SymTyp(α_3)}⟩$
抽象语义#
用图5来演示抽象语义
定义$U: exp → S → V$,表示表达式exp使得状态从S转换到了V

定义$F : stmt → S → S$表示语句stmt使得状态从S转换到了S

类型推断#
结构体推断#
当参数不是一个指针的时候,根据图六的抽象域能够相对轻松的推断出具体类型
但当参数是一个指针的时候,就不得不分析具体的内存状态来推断类型了,以图4为例
对于LINE 9,第二个参数的抽象值为$⟨⊥, {Heap(Line 3, 0)}, \emptyset>$,因此我们需要继续分析,内存在LINE 3处分配,然后我们搜索所有和$Heap(Line 3,∗)$相关的内存使用,可以找到$Heap(Line 3, 0)$和$Heap(Line 3, 4)$对这块内存的使用,最后确认结构体类型如右图
如果内存分配在栈上,那么分析会更加复杂

函数f在栈上分配了结构体s,在二进制层面,初始化结构体的s.x和s.y与初始化两个普通变量不会有任何区别,因此如果一个系统调用的参数是一个指向栈的指针的话,我们并没有办法去区分是一个结构体还是一个普通的变量。如果认为是一个结构体的话,那么就不得不识别结构体的边界
启发式方法:通过函数内存访问的启发式方法
- 如果定义了相邻的栈变量但未使用,那么认为是一个传递给syscall的结构体
- 如果被使用了但是未定义,那么认为是由syscall初始化的结构体变量
以图8为例,s.y在LINE 5定义,但未在函数中使用,因此认为它是结构体的一部分,相反的,k在LINE 6定义且在LINE 8使用,因此认为它不是一个结构体,具体实现上,在这里用到了可达性分析和活跃变量分析
数组推断#
数组推断主要采用了两种方法:
- 已知API中的数组可能会传到syscall中,在图9中,Data结构由SAL定义,表明buf的大小与n有关,当它传递到f时,我们就知道d->buf指向的是一个int数组

- 可以直接根据内存分配来推断,例如函数g中,可以根据内存分配关系确定它是一个数组
处理冲突#
当发生冲突的时候,由于会出现很多API都调用syscall的情况,所以选择投票表决的结果作为类型推断的最终结果
Fuzzer模块#
fuzzer模块通过拦截上层应用的系统调用来进行,在运行过程中动态改变系统调用的参数
Launcher#
使用基于Hook的fuzz技术,因此只需要对上层应用撰写相应脚本即可,这样上层应用执行到系统调用的时候,就可以执行被Hook的系统调用了,在实现中,直接修改SSDT表来进行对系统调用的Hook,由于在x86-64系统中无法这样操作,因此目前NTFUZZ只支持x86系统
Mutator#
在设计上主要遵从两个原则:1.利用类型推断的结果;2.突变后的输入不应该被系统调用错误处理程序卡住

利用类型推断的变异#
- 整型(
int,long...):策略同AFL,主要包含bit翻转,算数突变,极值,随机数 - 字符串(
char*,wchar_t*,...):字符替换,字符串扩充,字符串截断 - 句柄(Handle):无变异策略,因为修改Handle类型往往会引起错误处理程序
- 结构体:对结构体中的每个成员采取变异策略
- 数组(array):对数组中的每个成员进行突变
- 指针:除了对指针指向的类型进行变异外,也对指针采取整型变异策略
懒变异#
当遇到错误处理时,程序往往会卡住不继续执行,这样会导致前面的系统调用突变几率更大,而后面的几率小,导致了突变概率的不平衡
因此论文采取了懒变异的策略,如算法二所示,首先估计没有突变时产生的系统调用数目,然后取得平均值
在变异时,先生成随机数n,只对n次调用后的系统调用进行突变
Crash检测#
和用户态程序不同,系统出错会直接重启系统,十分耗费时间,因此将虚拟机配置为在系统崩溃时dump内存,并在重启后发送到主机,同时将系统编译的输入存储在内存中,这样也会一起被dump下来
NTFuzz评测#
RQ1:准确率和规模化程度如何
RQ2:突变率对Fuzz效率的影响
RQ3:类型推断的fuzz是否真的有效
RQ4:NTFuzz能否在最新版的Windows上找出漏洞,和其他的fuzz工具相比如何
实验设置#
运行环境:
- RQ1:Intel i7-6700 3.4GHz CPU and 64GB of memory
- RQ2-RQ4:two cores of Intel Xeon E5-2699 2.2GHz CPU and 4GB of memory to each VM running under VirtualBox- 6.1.0
Windows版本:
- RQ2:Windows 10 17134.1 build, released in April 2018
- RQ4:Windows 10 18362.592 released in January 2020
种子应用:
- AdapterWatch 1.05
- Chess Titans
- DxDiag
- PowerPoint 2019 10361.20002
- SpaceSniffer 1.3.0.2
- SumatraPDF 3.2
- Unity Sample
- WordPad
静态分析效果#
准确率
从API 文档中收集已知的结构信息:64个系统调用,326个参数作为ground truth,实验证明静态类型推断的准确率达到了69%。
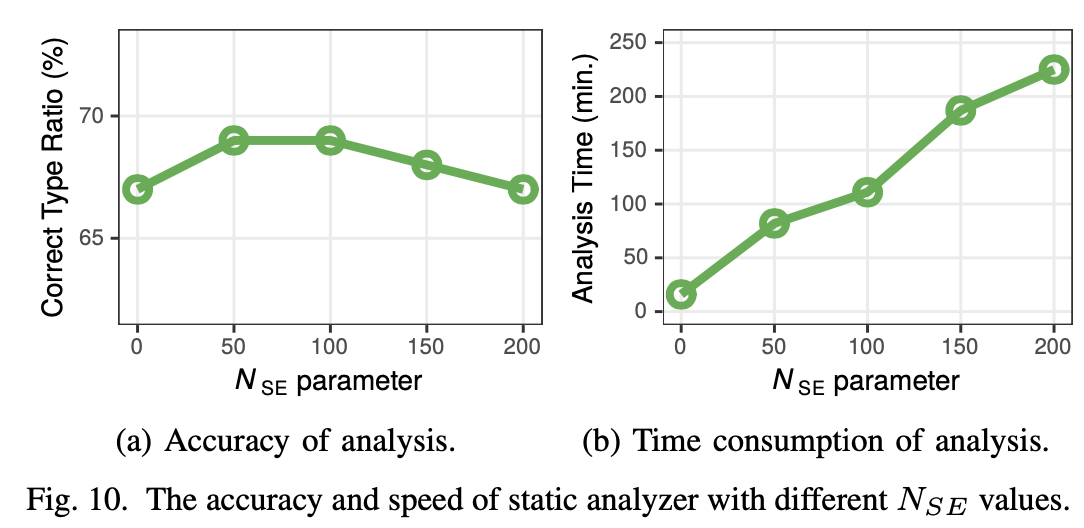
错误来源主要为:空指针以及栈上的结构体
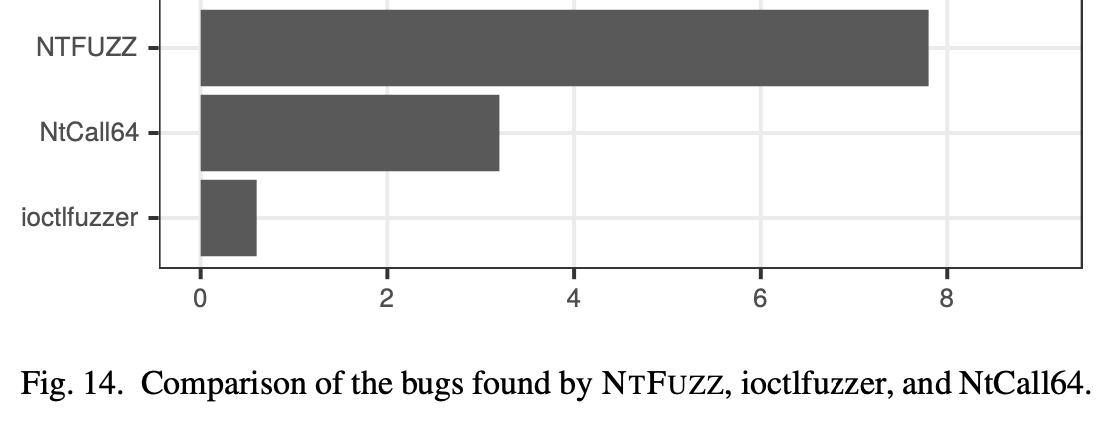
实验表明,类型推断能够帮助NTFUZZ发现1.7倍以上的新漏洞
规模化程度

表2说明NTFUZZ具备较大规模的分析能力
突变率影响#
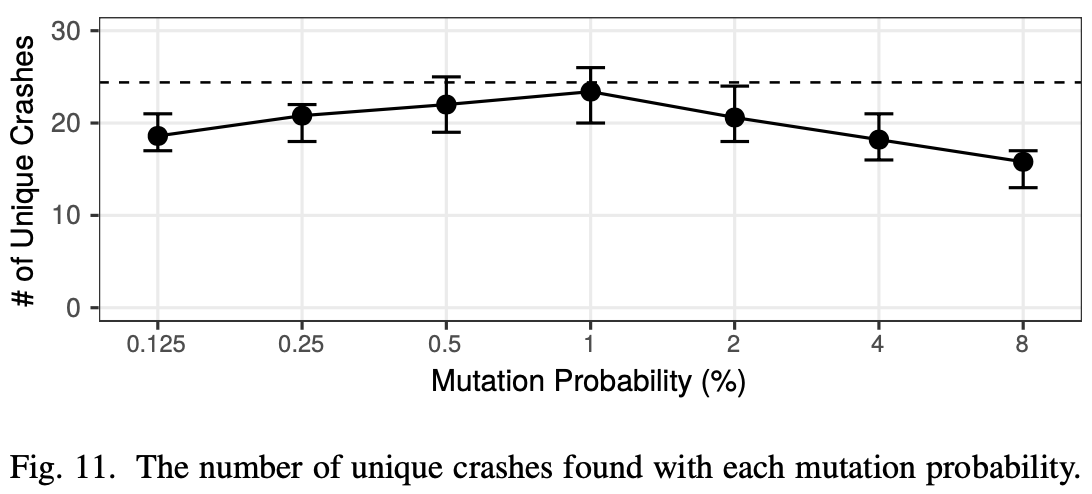
在fuzz中,对变异率的设置十分重要,实验设置突变概率为$p = 0.01 × 2^{-n}, n ∈ {−3, −2, …, 3}$,对NTFuzz的结果影响如图11所示
实验中对每个p运行48小时,获得了上面的结果
类型推断影响#
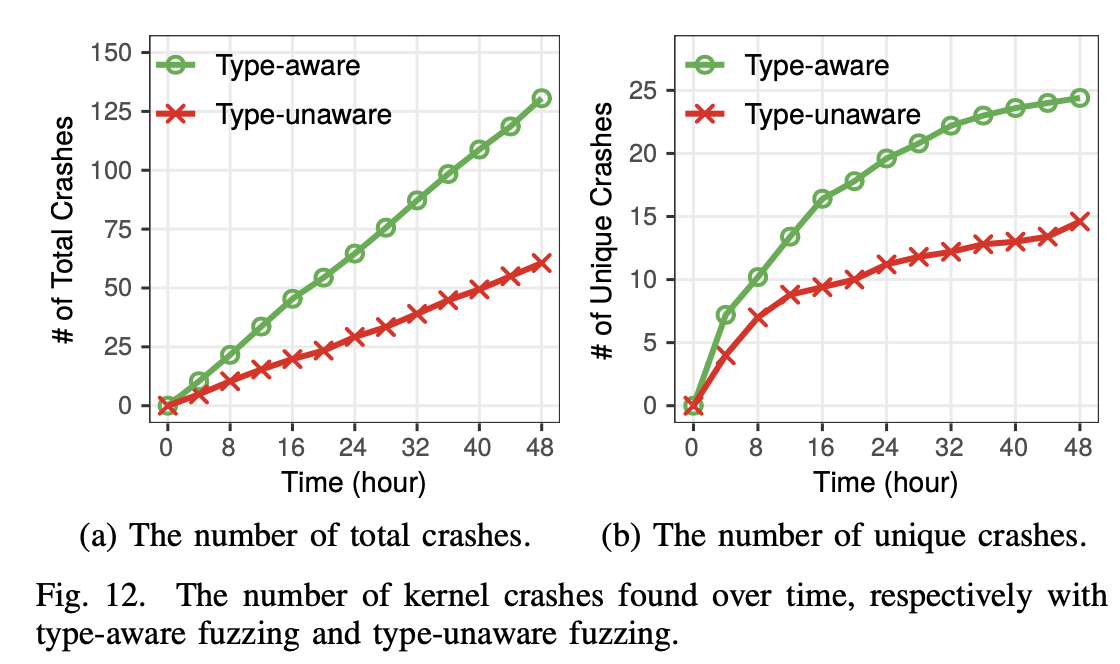
可以看到,类型推断能够为NTFUZZ找到更多的crash示例
真实漏洞发现#
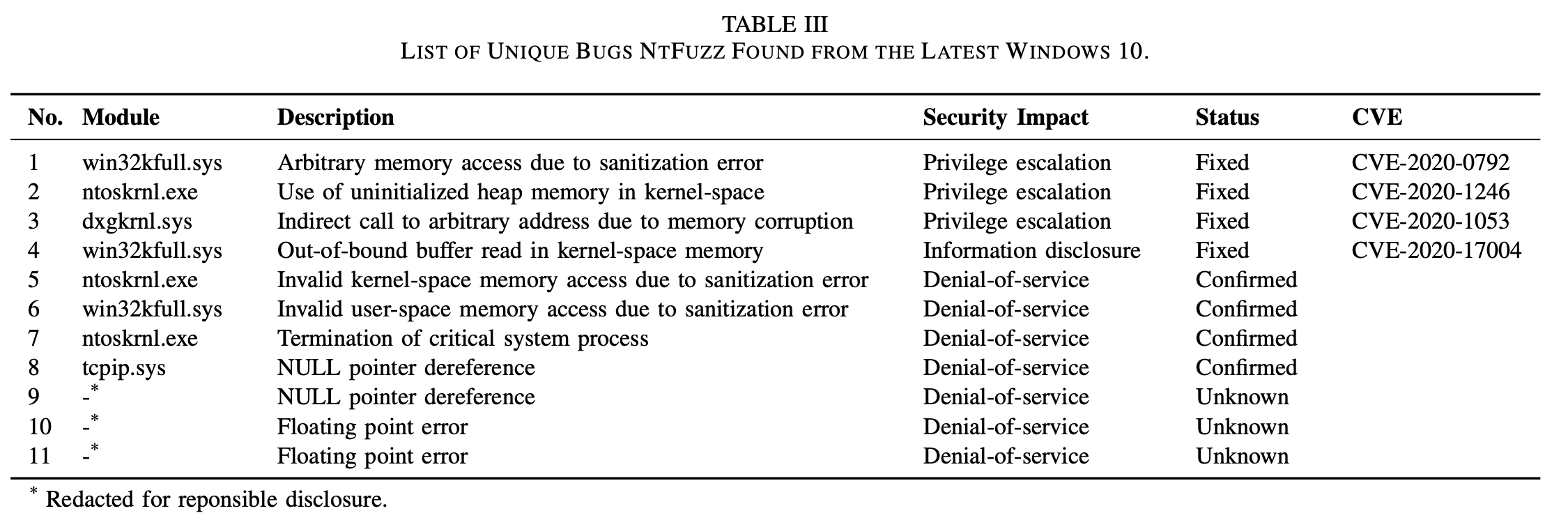
NTFUZZ在最新版的windows中发现了11个crash,如上,和同类fuzz工具相比,能找到更多的漏洞