SoK: All You Ever Wanted to Know About x86/x64 Binary Disassembly But Were Afraid to Ask(S&P 2021)
是一篇二进制分析工具的SoK文章,内容十分繁多,但是收获颇丰
二进制分析工具#
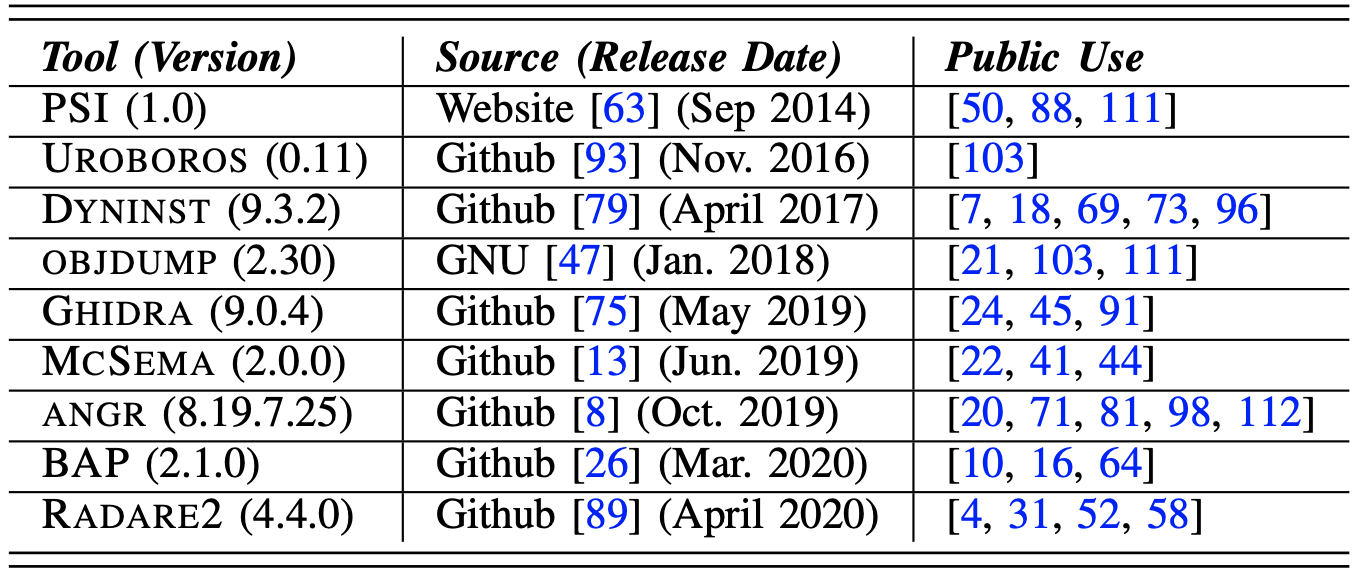
开源工具
- PSI:为了实现静态插桩实现的工具
- uroboros:一个指令反汇编的基础框架
- dyninst:二进制分析、检测和修改工具
- Objdump:gnu套间中的二进制信息查看工具
- Ghidra:NSA开发的逆向套件,对标IDA
- mcsema:用于将x86/x64等架构的二进制转换为LLVM 字节码的框架
- angr:二进制分析平台,主要应用于符号执行
- bap:二进制分析平台,包括静态分析和动态符号执行等
- radare2:逆向工程框架,命令行工具,cutter是对应的GUI工具
商业工具
- IDA Pro:一个强大的反汇编器和一个多功能的调试器,跨各种平台,有丰富的插件,支持Python
- Binary Ninja:与IDA类似,支持Python,有丰富的API
- Hopper Disassembler:Mac平台上的二进制分析工具
更多对比和参考
radare2提供了对 Radare2| Binary Ninja Demo | Binary Ninja | Hopper Demo | Hopper| JEB| IDA Pro的详细对比:https://raw.githubusercontent.com/radareorg/radareorg/master/source/comparison.rst
研究背景#
思考问题:
- 这些二进制分析工具的区别是什么,都有哪些优点和缺点
- 哪个工具更适合我们,我们该怎么选择
研究内容:
- 剖析二进制分析工具的分析技术,论文将分析技术分为两类:算法和启发式(Q1)
- 算法:算法的结果具有准确性保证,主要利用来自于二进制(符号表等)、机器(指令集)、ABI(调用约定)
- 启发式:基于总结的常见模式,不具有准确定保证,可能会引入错误
- 设计了一个分析框架,结合benchmark(3788),对现有工具进行分析和测试(Q2、Q3)
回答下面的问题:
- Q1:二进制分析工具中的算法和启发式有哪些,它们如何相互作用
- Q2:与算法相比,启发式的覆盖率和准确性如何,是否有一定取舍
- Q3:现有工具会产生哪些分析错误,根本原因是什么
一些综合性发现:
- 现有工具都在分析的各个阶段加入了启发式算法
- 启发式通常无法提供正确性保证并导致各种错误,尤其是在遇到复杂构造时,以前的工作可能高估了这些启发式方法的可靠性
- 一些工具可能共享同一组算法和启发式算法,但是,它们以不同的方式进行组合,从而导致不同的准确度-覆盖率
- 工具在不同的任务中具有不同的优势。例如,商业工具更擅长恢复指令,但开源工具可以更好地识别交叉引用。
二进制分析技术剖析背景#
功能划分#
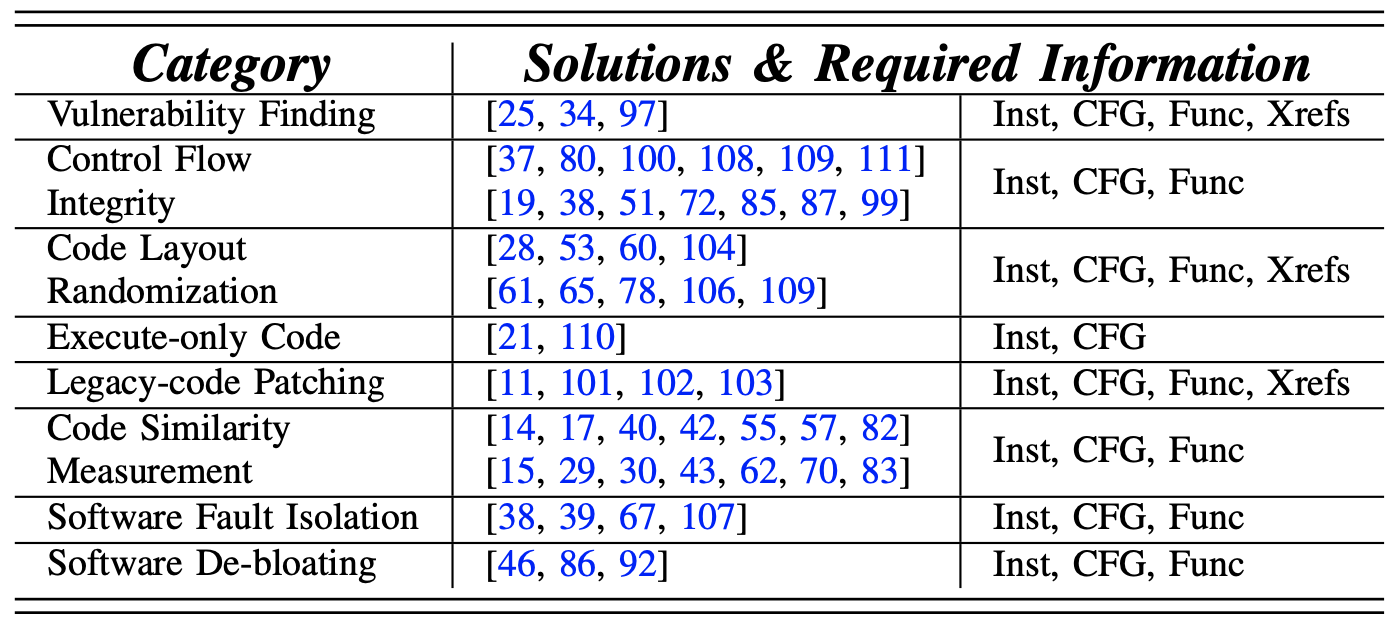
在二进制安全分析领域,大家会更加关注表中的信息,主要为指令恢复(反汇编),控制流图、函数识别以及交叉引用,相关技术如下:
- 反汇编:将二进制中的指令恢复出来,反汇编需要将数据与代码区域分开,并正确识别由编译器发出或由开发人员引入的指令
- 符号化:确定交叉引用,准确的确定二进制中作为其他代码或数据对象引用的数值。 根据参考位置和目标位置的不同,外部参照有四种类型:代码到代码 (c2c)、代码到数据 (c2d)、数据到代码 (d2c) 和数据到数据(d2d)
- 函数入口点识别:识别函数的入口点,尤其是main函数
- CFG重建:根据直接跳转,间接跳转等重建控制流图
目标二进制#
对于分析的二进制文件,具有如下假设:
- 由主流编译器和链接器生成的
- 二进制文件中可能包含手写的汇编代码
- 没有被混淆
- 假设无符号,即二进制文件被strip过
- 只考虑 x86/x64 二进制文件
- 能够在 Linux 或 Windows 操作系统上运行
目标工具#
对于目标工具的选择,主要基于下面的考虑:
- 能够进行二进制分析,或者具有独立的分析功能
- 能够在无用户交互的情况下进行分析
- 是开源工具,能够深入源码研究具体的策略
- 有其他工具没有完全覆盖的独特策略
- 可以运行目标二进制文件来支持定量评估
基于上面的考虑,选择了一开始表中的工具
除此之外,还有JakStab [59]、RetDec [32] 和 BinCat [12],但由于不满足考虑条件,所以没有列入其中
- JakStab:无法运行目标二进制文件
- RetDec:使用了初步的反编译策略,大家都用到了
- BinCat:需要人工交互
实验设置#
BenchMark
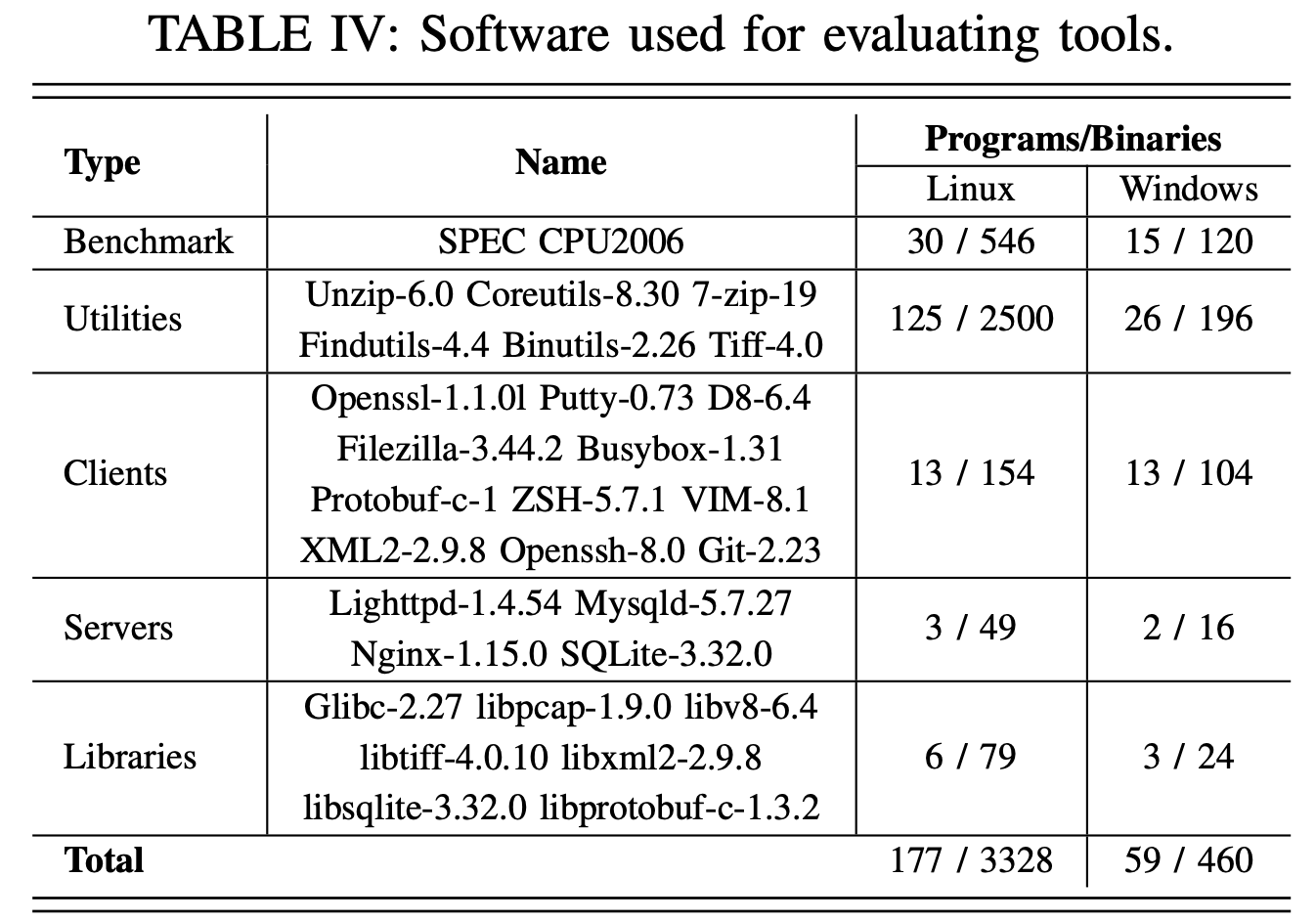
选择表中的软件构建benchmark,这些软件包括不同领域,使用C/C++编写,包含了硬编码和手写汇编,以及复杂的结构
在编译时,使用Linux gcc/llvm 和Windows下的Visual Studio进行编译,生成了不同编译选项(O0,O1,O2,Ox)以及两种架构(x86/x64)下的共3788个二进制文件
Ground Truth
在编译时收集相关信息,包括指令、函数、CFG、跳转表、交叉引用和其他复杂结构
- Linux下:扩展了LLVM(clang),也修改了gcc
- Windows下:结合编译器选项、符号/调试信息以及轻量级手动分析获得相关信息,(附件B)
PS:在实验中使用了两个版本的Ghidra和Angr,包括一个不使用异常信息的Ghidra版本,即Ghidra-NE,以及一个不使用线性扫描的版本,即Angr-NS。
二进制分析技术剖析和评测#
白底黑字的表示算法,黑底白字的表示启发式,总的分析结果如下

反汇编技术剖析#
目前的反汇编都基于两种算法:线性扫描和递归下降算法

线性扫描#
线性扫描 [OBJDUMP, PSI, UROBOROS]:扫描连续扫描预先选择的代码范围并识别有效指令,利用现代汇编程序倾向于连续布局代码以减小二进制文件大小的基本原理。 一般来说,线性扫描策略可以通过它如何选择扫描范围以及它如何处理扫描过程中的错误来描述。 因此,可以根据这两个方面总结
(1) 算法 [OBJDUMP, PSI, UROBOROS]:基于objdump的算法选择扫描范围,具体处理.symtab和.dymsym (包含section 信息) 中的符号指定的代码范围,一般里面都是合法的代码指令
[1] 启发式 [OBJDUMP, PSI, UROBOROS]:由于是线性扫描,因此都是连续的对指令进行扫描
[2] 启发式 [OBJDUMP]:Objdump扫描到无效的指令时,会跳过一个字节,重新开始扫描
[3] 启发式 [PSI]:除了无效指令,PSI将跳转到非指令数据也认为错误,PSI会反向追溯到第一个跳转指令,然后将中间的所有指令进行padding,最后重新进行分析
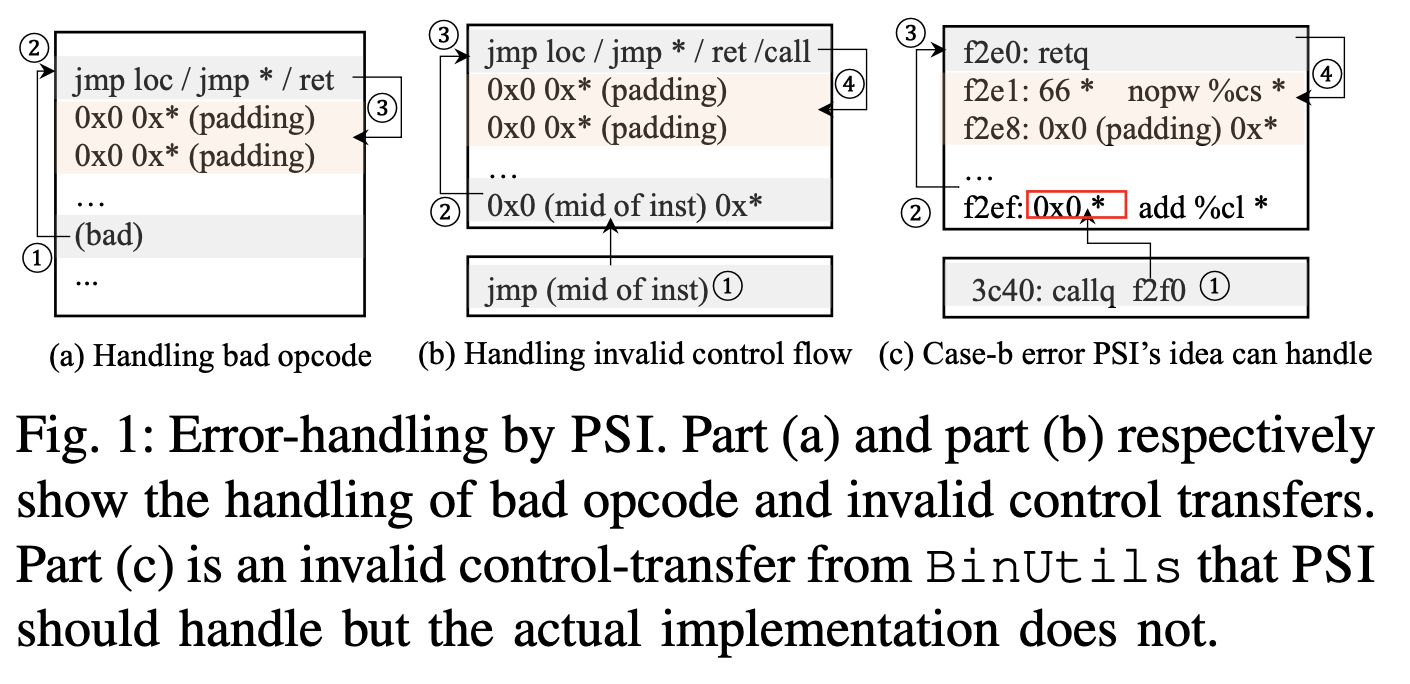
[4] 启发式 [UROBOROS]:uroboros将error处附近的指令都直接排除掉
SUMMARY
总的来说,线性扫描积极地扫描所有可能的代码,从而最大限度地恢复指令。 但是,由于代码中的数据,它可能会遇到错误。 为了解决错误,现有工具依赖启发式进行更正,但不够全面,实用性有限
递归下降#
递归下降 [DYNINST, GHIDRA, ANGR, BAP, RADARE2]: 从给定的代码地址开始,根据控制流进行反汇编,主要策略包括:1. 如何选择起始地址;2.如何处理控制流;3.如何处理递归下降后剩余的间隙
(2) 算法 [DYNINST, GHIDRA, ANGR, BAP, RADARE2]:由于是递归下降,因此都根据控制流进行反汇编
(3) 算法 [DYNINST, GHIDRA, ANGR, BAP, RADARE2]:都选择从代码入口点,main和符号表中获取代码块信息进行分析
对于直接控制流的处理是比较简单的,但是对于间接控制流,以及没有ret的函数,就比较困难。
由于间接控制流的静态难以判定性,递归下降往往会留下分析缺口,评估显示,当只使用递归下降时,会错过49.35%的代码,因此需要大量的启发式方法增加代码的覆盖率。
[5] 启发式 [DYNINST, GHIDRA, ANGR, BAP, RADARE2]:基于常见的函数序言/结尾或预训练的决策树模型在代码间隙中搜索函数入口点,评估显示该启发式能增加31.55%的代码覆盖率
[6] 启发式 [Angr]:Angr还会对剩下的代码间隙通过线性扫描增加覆盖率,如果在扫描中出现错误,angr会跳过当前的基本块并移动到下一个字节继续扫描。 这种线性扫描将Angr的代码覆盖率提高了约 8.20%。 但是,它会将数据错误地识别为代码
[7] 启发式 [Ghidra]:Ghidra增加了交叉引用的信息帮助分析,提高了4.33%的覆盖率
SUMMARY
严格的递归下降确保了正确性,但覆盖范围不足。 为了扩大代码覆盖范围,现有工具结合了许多破坏正确性保证的激进启发式方法。反汇编技术评测
反汇编技术评测#
评估分析工具对合法的指令恢复情况。 排除了所有填充字节和链接器插入的函数(例如,_start),同时为了公平,还插入了一个 main 符号,以便所有递归分析工具都能找到它
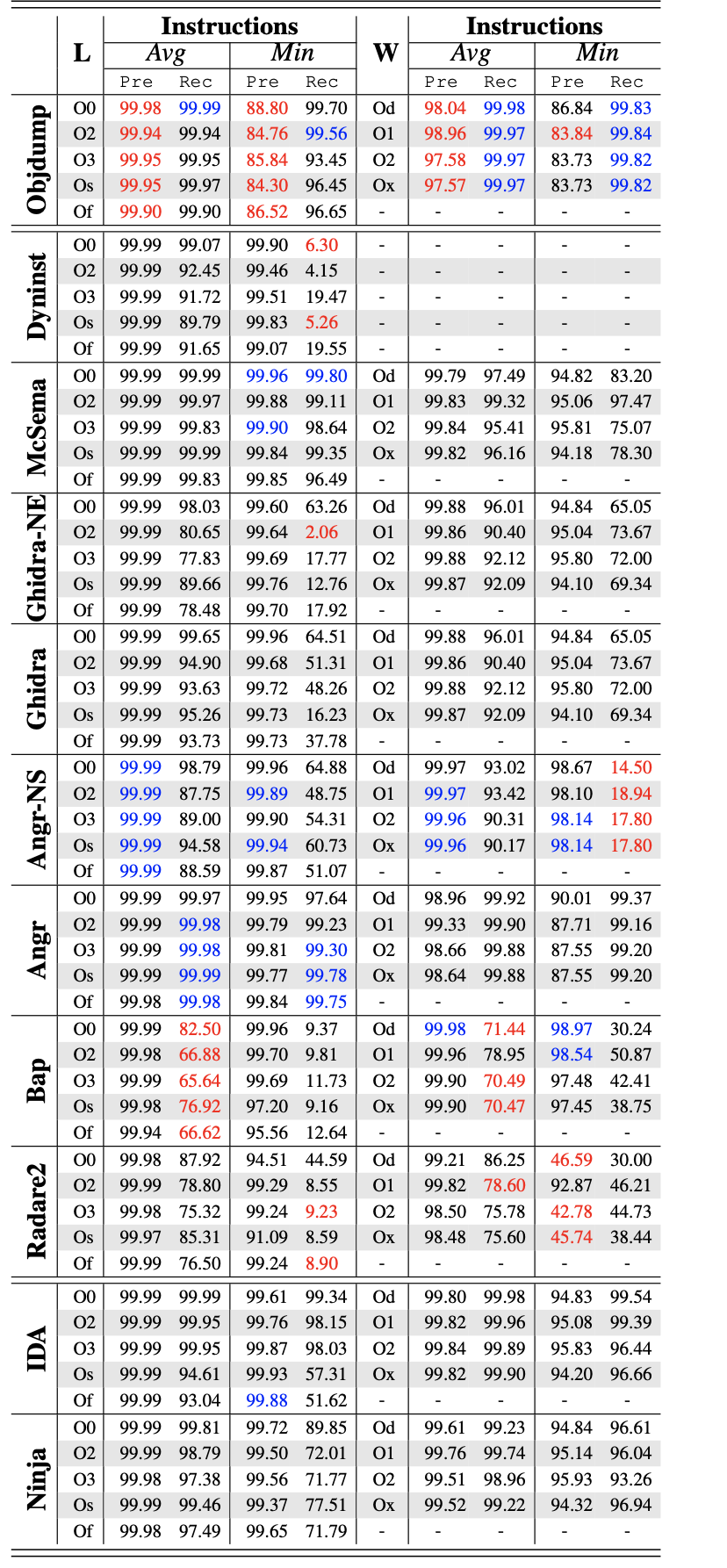
pre表示准确率,rec表示召回率;蓝色表示最好,红色表示最差
综合性结论#
覆盖率结论:
线性扫描工具,如Objdump 和 Angr,具有很高的覆盖率(99.95%+ 召回率)。 递归下降工具的覆盖率较低,有些只能恢复不到 80% 的指令(Bap 和 Radare2)。 而且递归工具的性能会随着优化级别和架构而变化。 几乎所有的递归工具(Angr-NS、Ghidra-NE、Dyninst、Bap、Radare2)的覆盖率都会随着优化级别的增加而降低。 这是因为优化级别和架构会影响递归工具中的函数匹配,进一步导致指令丢失。这样的结果很好地符合了前面的分析
准确性结论:
无论编译器、架构和优化级别如何,递归分析工具都具有很高的准确率(超过 99.5%)。 线性工具反而不太准确, 在在最坏的情况下,Objdump 的准确率下降到 85% 左右。 这种差异主要是因为递归工具大多遵循控制流,确保了正确性。 但是,线性工具会扫描每个字节,并且在代码中出现数据时经常会出错。 例如,Objdump在分析 Openssl 时产生最差的结果(精度:85.35%),因为 Openssl 在汇编文件中有大量的data,而 Objdump会错误地将数据识别为代码
启发式的使用#
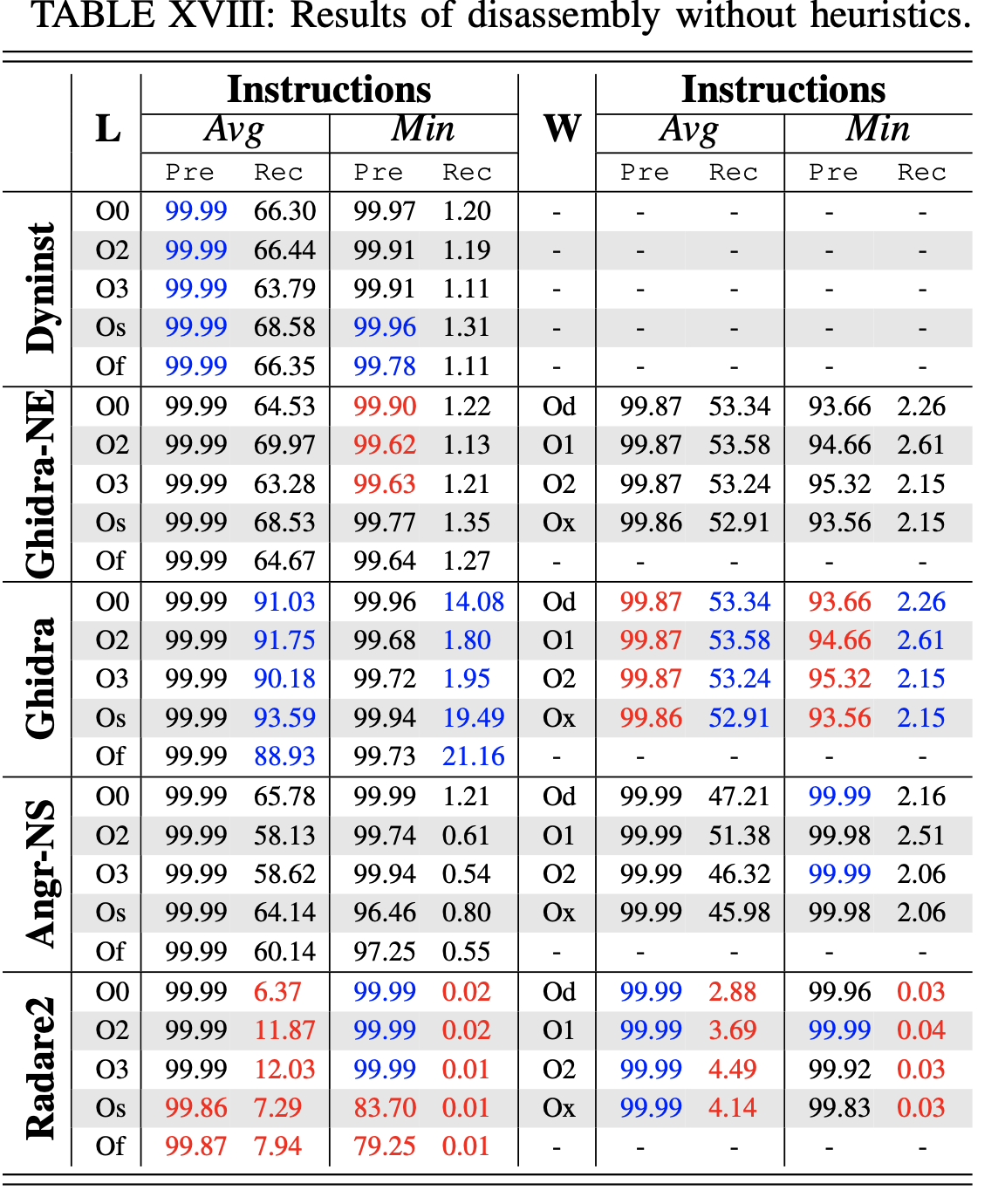
在二进制文件上,线性扫描会产生超过 10K 的错误。 PSI 启发式方法可以捕获线性扫描中 32% 的错误
相比之下,递归下降的启发式主要为了增加覆盖率。但是,如果没有启发式方法,这些工具的覆盖率会非常低。 Angr、Ghidra、Dyninst的召回率都在 51% 左右,而 Radare2 恢复的代码不超过 10%。 但是, Ghidra 仍然对 Linux 二进制文件产生高召回率。 这是因为 Ghidra 使用了交叉引用的信息来帮助分析
错误引入#
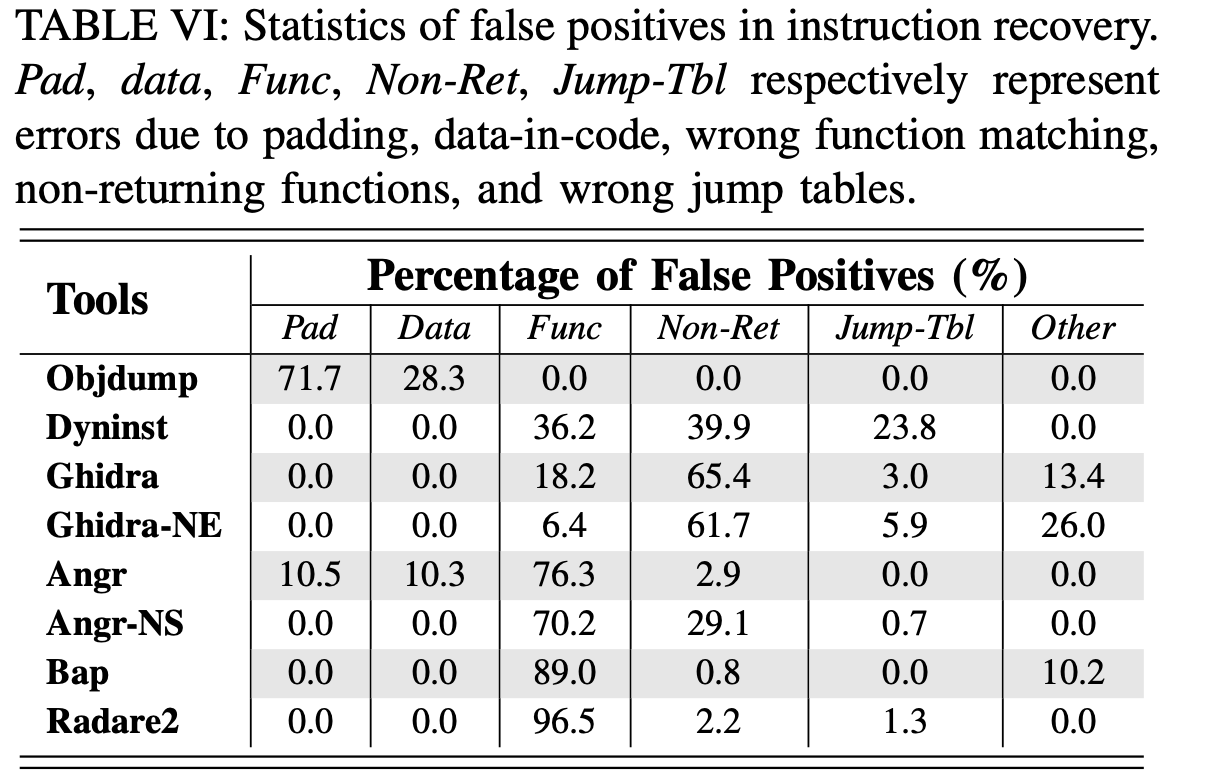
对于线性工具(例如 Objdump),所有误报都是由将填充字节或代码中的数据错误识别为代码引起的。对于递归工具,最常见的错误原因包括(1)将非法地址视为函数入口; (2) no-return函数分析有误; (3)跳转表解析不正确。除此之外,由于代码可能存在数据,angr 的线性扫描会导致 21% 的错误; Bap和 Ghidra 有一些实现缺陷,也导致了一些错误。
符号化技术剖析#
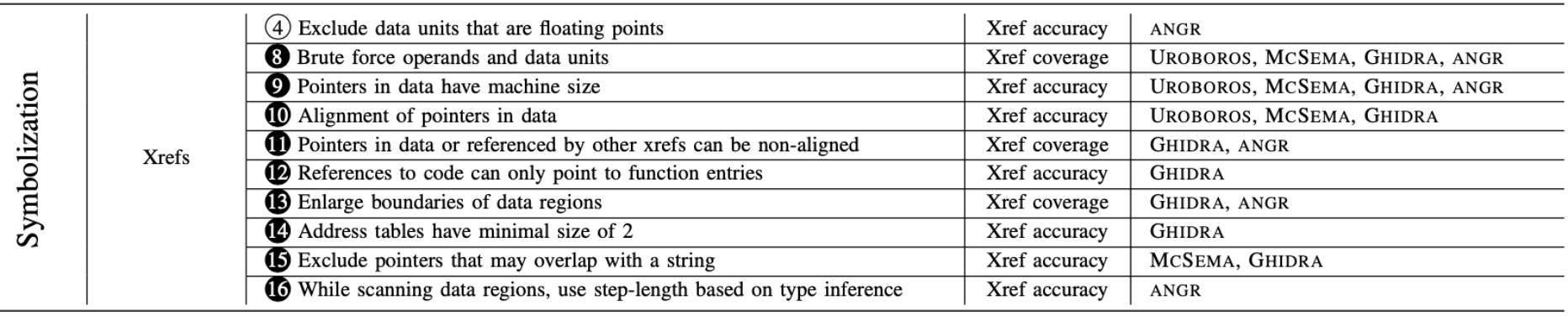
符号化用于标识二进制中的数值,这些数值实际上是对代码或数据对象的引用
数据提取#
[8] 启发式 [ANGR, GHIDRA, UROBOROS, MCSEMA]:搜索指令,识别常量操作数和可能的指针,并扫描非代码区块查找数据单元。通常一个数据单元由位于对齐地址的连续n个字节组成,但是,不同的工具对 n、对齐和非代码区域有不同的选择
[9] 启发式[ANGR, GHIDRA, UROBOROS, MCSEMA]:所有的分析工具都假设数据单元大小应该和机器大小一致,x86 4字节 / x64 8字节,但这并不是完全正确的,比如64位下的跳转表可能是4字节的
[10] 启发式 [GHIDRA, UROBOROS, MCSEMA]:uroboros 和 mcsema 使用机器字节对齐
[11] 启发式 [ANGR, GHIDRA]:除非数据单元为另一个数据的引用,否则Ghidra假定4字节对齐 / Angr没有对齐的要求,因为它观察到了指针存在不对齐的情况
评估表明,对齐的选择是一种覆盖精度的权衡:大约 600 个指针保存在未对齐的地址,而无对齐的假设导致了angr近 60% 的误报。
除了数据段之外,Ghidra 和 angr 还从非反汇编代码区域中搜索数据单元。
数据单元类型推断#
Angr会识别来自数据单元的内存负载。 如果加载的值流向浮点指令,angr会将数据单元标记为浮点数
Ghidra使用了比较激进的策略:如果给定一个常量操作数“指向”数据单元,且数据单元后跟一系列 ASCII/Unicode 字节和空字节,则认为该数据单元是字符串的开头,同时,满足下面条件的数据单元会被认为是指针
- 值大于4096
- 是指令地址或者不是代码段地址
- [12] 启发式 [Ghidra]:如果这个值是已知函数中的地址,那么必须是函数的入口点
因此Ghidra的类型推断没有准确性保证
C2C,C2D交叉引用#
对于每个常量操作数,angr、uroboros 和 mcsema都试图将其符号化为代码指针,并检查操作数是否引用合法指令
Ghidra的额外策略:
操作数不能是0-4095,0xffff,0xff00, 0xffffff, 0xff0000, 0xff0000, 0xffffffff, 0xffffff00, 0xffff0000, 0xff00000中的值
[12] 启发式 [Ghidra]:被引用的指令必须是函数的入口点。
在评估中发现数千个指针指向函数中间(例如,异常处理中用于 try-catch 的指针),表明启发式 12 是不合理的。
对于不可能是代码指针的常量操作数,工具会尝试将其符号化为数据指针,检查操作数是否指向合法的数据位置
- [13] 启发式 [Ghidra, Angr]:Angr和Ghidra在检查过程中,将数据区域的范围增加了1024,因为有一些指针会使用偏移来解引用,这个方法确实有效,但也引入了一些错误


地址表#
除了常量操作数,一些工具还通过扫扫描非代码区域来定位地址表:是连续的,由指针组成的数据单元集合
[14] 启发式 [Ghidra]:Ghidra 将 2 视为地址表的最小大小虽然选这有助于更准确地识别分组指针(如函数表),但它会遗漏许多单独的指针,从而导致误报。
(4) 算法 [Angr]:angr去除代表浮点数的表条目
[15] 启发式 [Mcsema, Ghidra]
Mcsema排除可能和字符串重叠的表条目,如果一个条目可能是地址也可能是字符串的话,mcsema更倾向于字符串,而angr正相反
Ghidra排除指向恢复函数中间的表条目,也排除与字符串重叠或切入其他指针的表条目。 最后,当相邻条目的距离大于 0xffffff 时,Ghidra会拆分地址表
[16] 启发式:angr在暴力搜索数据区域时使用特殊策略。 给定一个位置,angr会依次检查里面的数据是指针、ASCII/Unicode 字符串还是算术序列。 如果任何类型匹配,ANGR 跳过输入的字节,然后继续搜索,这个策略引入了大量的误报
SUMMARY
符号化过程缺乏算法支撑,暂时没有好的解决方案,各个工具都是引入了自己的启发式方法,在覆盖率和准确率上做了一个平衡
符号化技术评测#
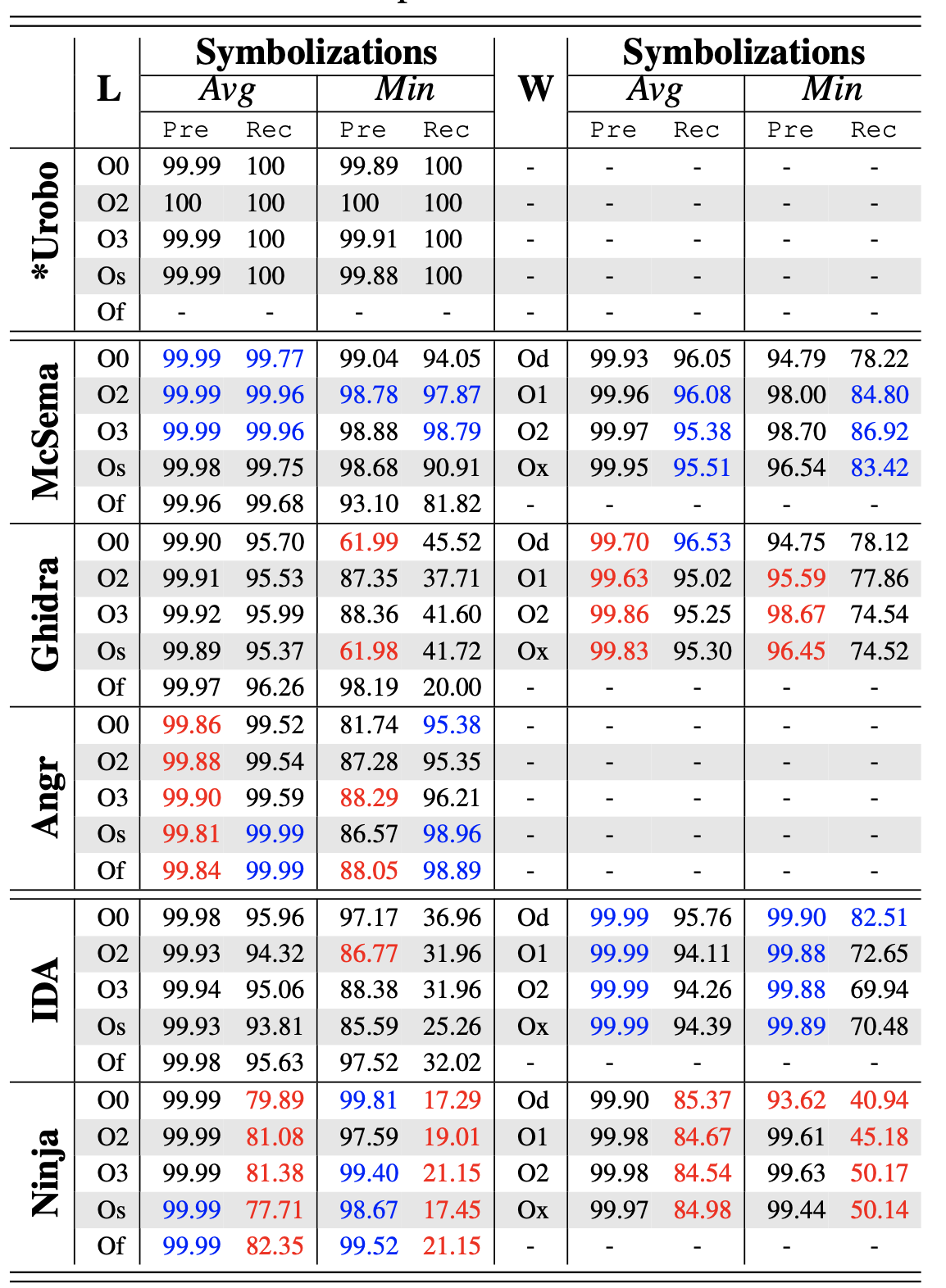
综合性结论#
总的来说,开源工具的召回率比商业工具高很多,这是因为开源工具暴力搜索了所有常量操作数和数据单元,而商业工具采用更保守的策略。同时,开源工具也具有很高的准确率(平均 99.92%)。 根据观察,高精度是因为
(1)基于启发式的搜索都是受限的
(2)大多数测试程序的数据较少。 在数据较多的程序上,开源工具更容易出错
启发式的使用#
启发式 8(基于暴力搜索的方法)对于符号化是必要的。 这可以通过比较 IDA PRO 和 MCSEMA 来验证。 MCSEMA 为 IDA PRO 增加了一轮暴力搜索,将覆盖率从 95% 提高到 98%
启发式9 (假设数据中的指针size为机器size),当不考虑跳转表时,在600万个xrefs中没有发现与假设相悖的
启发式10(数据中的指针是对齐的)和11(数据中的指针可能不对齐)相互冲突,两者都不是完美的。 启发式 10 遗漏了大约 600 个外部参照,而启发式 11 在 ANGR 中引入了大多数误报(超过 50K)
启发式 12(如果这个值是已知函数中的地址,那么必须是函数的入口点)可以减少误报,但它会错过函数中间的数千个外部引用(例如,异常处理中的 try-catch 指针)
启发式 13(扩大数据区域的边界)有助于恢复数据中的 12K 外部引用,但在 ANGR 和 GHIDRA 中导致 6 和 2K+ 误报。
启发式 14 (将 2 视为地址表的最小大小) 在 GHIDRA 中引入了大量漏报(fn),尽管删除了一小部分误报(fp)
启发式15 (如果一个条目可能是地址也可能是字符串的话,mcsema更倾向于字符串)在 MCSEMA 中产生超过 3K 的漏报,因为它对字符串的推断不准确
错误引入#
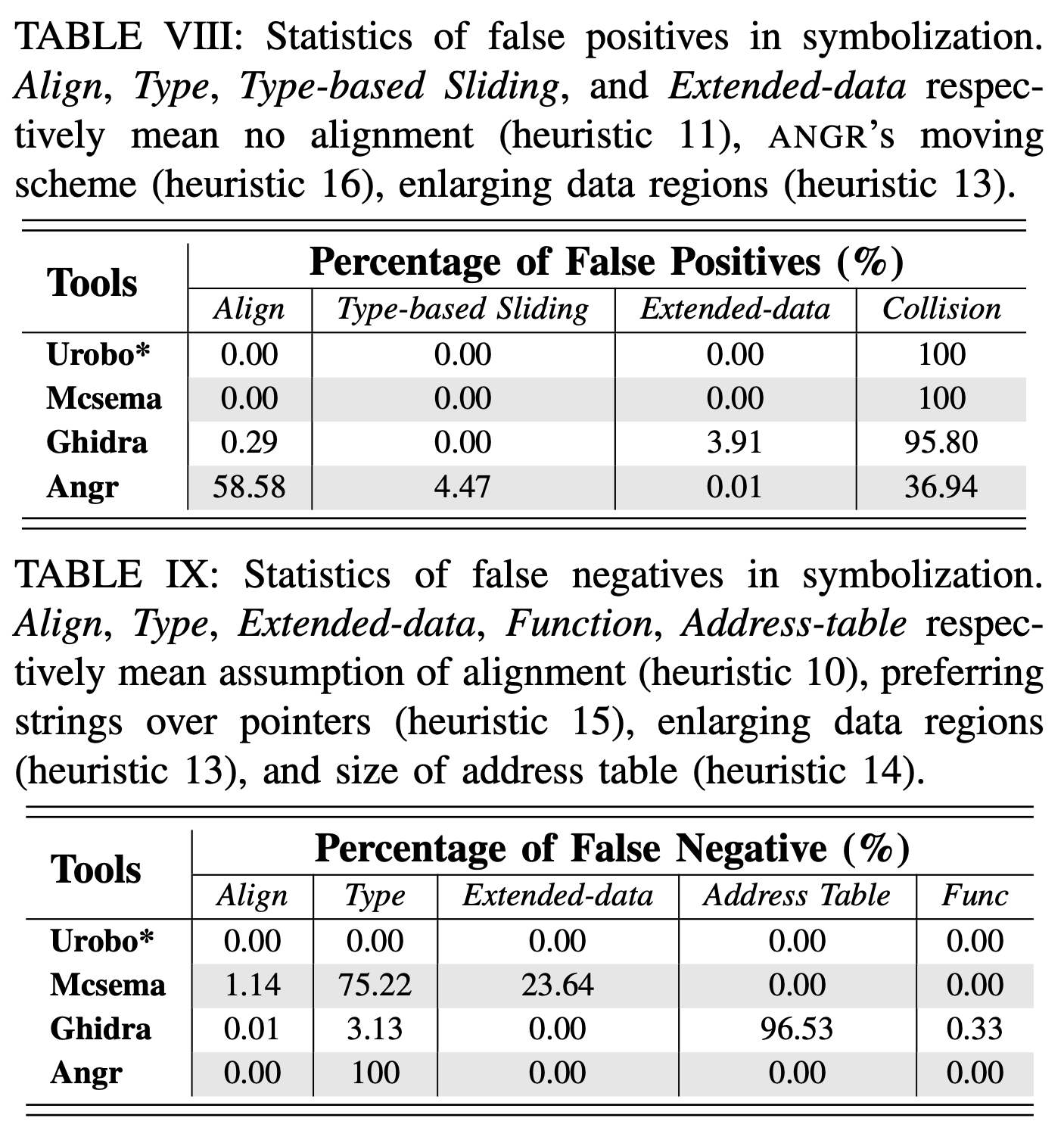
#
假设数据中的指针可以不对齐,ANGR 和 GHIDRA 会出现 59% 和 0.3% 的误报。 同时扩大了数据区域的边界也引入了误报。 所有其他误报都是由于数值和指针之间的冲突造成的。
ANGR 和 MCSEMA 的大多数误报是因为它们排除了与推断字符串重叠的指针。 MCSEMA 还遗漏了 23.64% 的交叉引用,这些引用指向数据区域之外的位置。 GHIDRA 假设地址表的最小大小为2,并且代码指针始终指向函数条目,因此分别产生了 96.53% 和 0.33% 的漏报。
函数入口识别技术剖析#

大多数工具会使用单独的策略来识别main函数
main函数#
- (5) 算法 [Bap, Angr]:angr和bap会找到_start函数,它会调用__libc_start_main,其中的第一个参数就是main函数

- [17] 启发式 [Dyninst, Radare2]:radare2和dyninst在__libc_start_main调用附近找特定于架构的特征来找到main函数。
- dyninst在调用之前找到指令并提取立即数操作数
- Radare2 在固定的原始字节序列之后搜索地址,如图1中的48 c7 c7,对于 Windows 二进制文件,Radare2 在 __scrt_common_main_seh 中寻找类似模式
通用函数#
为了识别不是main函数的函数,这些工具采用了由三部分组成混合的方法
(6) 算法 [Dyninst, Ghidra, Angr, Bap, Radare2]:扫描.symtab 和 .dynsym 部分中剩余的符号来确定已知的函数
(7) 算法 [Ghidra]:Ghidra会扫描.eh_frame中的信息
(8) 算法 [Dyninst, Ghidra, Angr, Bap, Radare2]:扫描函数中存在的直接调用来确定入口点
(9) 算法 [Ghidra, Angr]:angr和Ghidra会处理一些间接调用,帮助恢复信息
最后,他们都会处理尾调用,作为函数的入口点
尾调用
在return时调用函数称为尾调用,比如下面对函数m和函数n的调用
2
3
4
5
6
if (x > 0) {
return m(x)
}
return n(x);
}
[18] 启发式 [Dyninst, Ghidra, Angr, Bap, Radare2]:所有的工具都会实现自己的启发式,去寻找函数的序言或结尾,例如dyninst和bap使用预训练的决策树来寻找函数
[19] 启发式 [Angr]:angr 采用了一种更激进的方法:在对递归下降留下的代码间隙进行线性扫描期间,它将每个识别出的代码段的开头视为一个新的函数入口点。 这种方法提高了覆盖率,但会产生很多错误
SUNMARY
函数入口的识别大多采用混合方法、混合算法和启发式方法
函数入口识别技术评测#
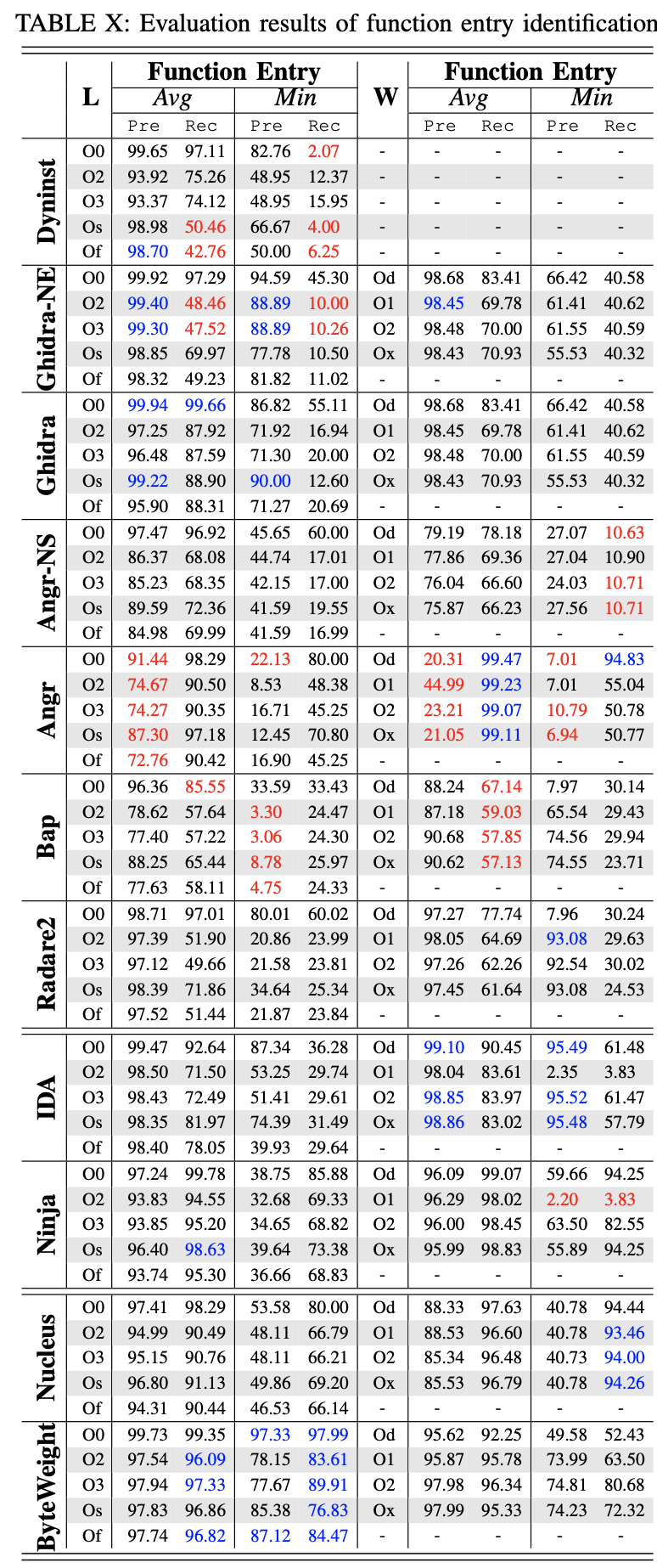
综合性结论#
函数入口识别仍然是一个挑战,4个开源工具都只能识别不到80%的函数。 特别是,radare2 的召回率低于 66%。 这样的结果表明,即使使用启发式方法,我们还没有开发出很好的函数识别工具。
函数识别的结果因优化级别和架构而异。 这是因为这些工具广泛使用基于签名的函数匹配,这种匹配模式与优化和架构十分相关。 除了覆盖范围有限之外,与指令恢复和符号化相比,现有工具在函数识别方面的准确率也较低。 例如,Angr 和 Bap的平均准确率分别为 56.67% 和 86.11%。
商业工具比开源工具的效果更好。 特别是 Binary Ninja 可以识别超过 97% 的函数,准确率超过 95%。 其次,NUCLEUS 达到了与 Binary Ninja相当的覆盖范围和精度,显示了其基于 CFG 连接的解决方案的高前景。 基于官方博客 [84],Binary Ninja 结合了 NUCLEUS 用于 CFG 和函数检测。 第三,尽管 BAP 内部运行 BYTE WEIGHT,但 BYTEWEIGHT 优于 BAP。 这是因为 BAP 使用预训练的签名,而 BYTEWEIGHT 使用我们的基准二进制文件训练的签名。
启发式的使用#
第一个启发式使用常见的序言/数据挖掘模型搜索函数条目。 该启发式恢复了 17.36% 的函数,平均准确率为 77.53%。 同样,这种启发式方法的效过也与优化级别和架构十分相关。 现有工具使用不同的模式或数据挖掘模型,在覆盖范围和准确性之间进行权衡。 与 GHIDRA-NE 和 RADARE2 相比,ANGR-NS 和 DYNINST 使用更激进的模式/模型,产生更高的覆盖率(21.3%/24.02 vs 18.24%/7.93%)但精度较低(56.61%/85.37% vs 98.42%/87.29%) )。
ANGR 使用的另一种启发式方法将线性扫描检测到的每个代码区域的开头作为函数条目。 启发式方法多恢复了 23% 的函数,但将精度降低了 26.96%,因为它通常将填充的开始或代码中的数据视为函数条目。
错误引入#
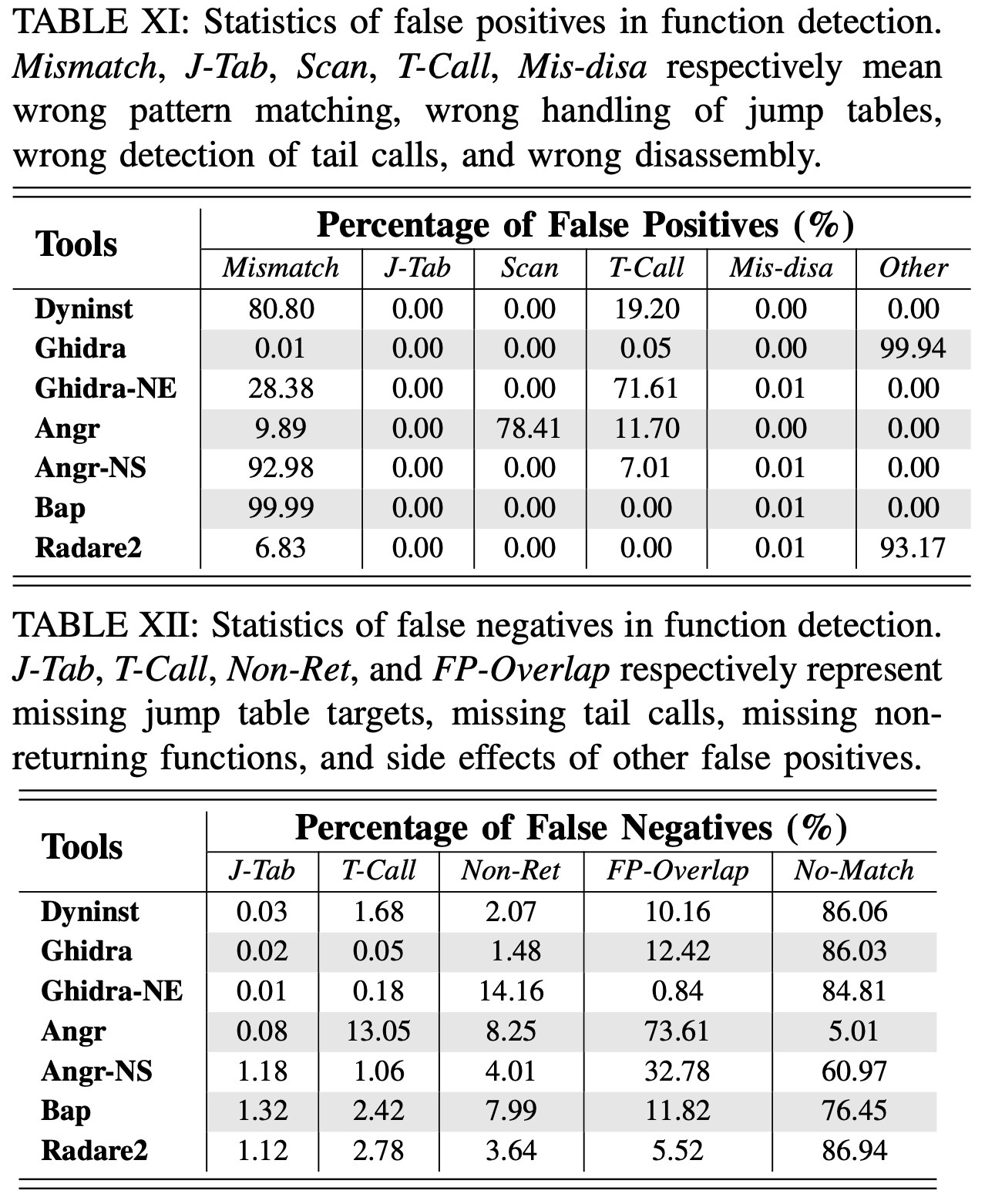
误报原因:
首先,基于函数签名的入口点检测会导致错误
其次,不准确的尾调用检测会常规跳转的目标作为函数入口
第三,不正确的反汇编导致错误的目标函数调用指令
除了这三个原因之外,ANGR 会产生 78.41% 的误报,因为它将线性扫描发现的代码视为函数入口; GHIDRA 产生了 99.94% 的误报,因为交叉引用信息中带有指向函数中间的指针;
漏报原因:
首先,工具可能会错过跳转表的目标,并且无法识别目标代码或其后继调用的函数,跳转表对 ANGR 和 DYNINST 的影响较小,因为 ANGR 使用线性扫描来补偿跳转表,而Dyninst具有较高的跳转表覆盖率。
其次,工具无法识别许多尾调用,因此会错过其目标指示的函数
第三,错过的非返回函数会阻止检测到许多函数条目
第四,错误识别的函数可能与准确的函数重叠,使原本的函数无法被识别
所有其他函数都被遗漏了,因为它们既不能通过递归下降到达,也不能通过模式匹配识别
CFG 重建技术剖析#
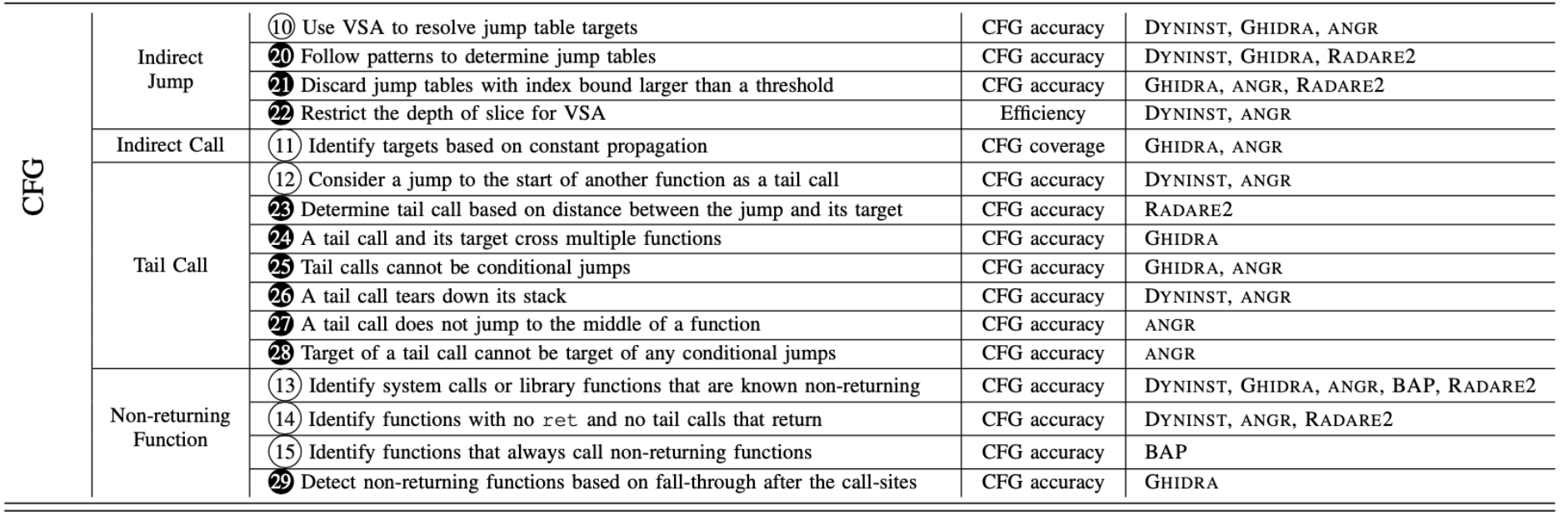
CFG重建由许多部分组成,这里主要分析存在挑战的部分,即间接跳转/调用、检测尾调用和No-return函数
间接跳转#
主要存在下面三类间接跳转:
- 从if else语句,switch 语句编译而来的跳转表
- 间接尾调用(优化为尾调用的间接调用)
- 手写的跳转语句
[20] 启发式 [Dyninst, Ghidra, Radare2]:radare2只处理了4种模式的跳转表,以Type-1跳转表为例,radare2会在前面的基本块中搜索jmp [base + reg * size]形式的间接跳转和cmp/sub指令。 radare2 在找到这两项时,将 base 视为基址,将 cmp/sub 中的常量操作数视为索引的上限。
[21] 启发式 [Dyninst, Angr, Radare2]:如果该上限超过 512,radare2 将丢弃跳转表
radare2的实现对编译选项高度敏感,解析跳转表效果较差

dyninst也只处理了跳转表,但是方法有所不同
[22] 启发式 [Dyninst, Angr]:从目标执行向后切片。 在切片区域中,如果第一次读取的内存(简化后)的格式为[CONST + reg * size] ,则dyninst认为间接跳转是一个跳转表,分别使用CONST和reg作为基地址和索引。 从索引开始,dyninst 再次执行后向切片,最多切出50 个赋值语句或到达函数到达入口点。 在此切片中,dyninst使用简化的值分析 (VSA) 确定边界

[20] 启发式 [Dyninst, Ghidra, Radare2]:Ghidra将间接跳转视为跳转表,在当前函数中,Ghidra 寻找定义基地址和索引的单个路径。 沿着路径,GHIDRA 跟踪base和索引的传播以识别它们的值界限。 Ghidra不使用完整的 VSA,而是考虑变量类型、条件跳转和指令的限制,和radare2相似,Ghidra也设置了上限为1024
如果无法处理为跳转表,Ghidra会将它认为是间接调用
angr在遇到间接跳转时,会将操作数视为源并做反向切片。 在切片区域,angr使用完全的VSA来识别可能的目标。 但是,angr 的公共版本将切片限制为最多三个基本块,以换取效率。 angr也采用了启发式 21,阈值非常大:100,000
SUMMARY
工具采用各种启发式方法来解决间接跳转。 这些启发式方法主要是为了准确性而衍生的,引入的错误较少,但覆盖范围有限
间接调用#
(11) 算法 [Ghidra, Angr]:Ghidra 基于持续传播找到间接调用的目标 。 它跟踪来自立即操作数、LEA 指令和全局存储器的常量的过程内传播。 一旦常量流向间接调用,Ghidra 就会将该常量作为目标。 angr也使用常量传播来处理间接调用,但只考虑当前的基本块
尾调用#
尾调用优化为跳转
在return时调用函数称为尾调用,比如下面对函数m和函数n的调用
2
3
4
5
6
if (x > 0) {
return m(x); -> jmp 到函数m继续执行
}
return n(x); -> jmp 到函数n继续执行
}
为了执行效率,过程末尾的函数调用通常会被优化为跳转(即尾调用)。 工具采用不同的策略来检测尾调用
[23] 启发式 [Radare2]:radare2 使用简单的启发式方法来确定尾调用:跳跃与其目标之间的距离超过某个阈值。 这种启发式方法利用了不同函数通常是分开的这一见解。 然而,很难选择一个既有效又准确的阈值。
[24] 启发式 [Ghidra]:Ghidra在处理时,如果跳转与其目标之间的代码跨越多个函数,则将跳转确定为尾调用。这一 启发式会导致由于不连续函数产生的误报和由于无法识别的函数产生的漏报。
[25] 启发式 [Ghidra, Angr]:Ghidra进一步将条件跳转排除在考虑范围之外, 导致了21.6% 尾调用的漏报。
(12) 算法 [Dyninst, Angr]:如果跳转目标是已知函数的开始,dyninst会将跳转视为尾调用
**[26] 启发式 [Dyninst, Angr] **:如果不是已知函数的开始,dyninst会采用下面的启发式来确定是否为尾调用
规则一:仅跟随错误分支无法到达跳转的目标
规则二:在跳转之前,堆栈为
[leave; pop $reg] 或 [add $rsp $const]
虽然第一条规则难以推理,但第二条规则利用了尾调用的内在属性:当前函数回收堆栈,以便子函数重新使用其返回地址。 上述基于模式的方法不太准确,导致了97% 的误报和漏报
(12)算法 [Dyninst, Angr]:angr和dyninst一样识别跳转目的是否为已知函数的开始
除此之外,angr还根据4个条件来检测尾调用
- [25] 启发式 [Ghidra, Angr] :无条件跳转
- **[26] 启发式 [Dyninst, Angr] **:分析栈顶的情况
- [27] 启发式 [Angr]:跳转目标不是任何函数
- [28] 启发式 [Angr]:跳转目标的所有入边都是无条件跳转或直接调用
SUMMARY
工具采用不同的策略来检测尾调用。 这些策略严重依赖于函数入口检测,因此受函数识别的准确性的影响
No-return 函数#
No-return 函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <stdio.h>
noreturn void stop_now() {
abort();
}
int main(void)
{
printf("Preparing to stop...\n");
stop_now();
printf("This code is never executed.\n");
return EXIT_SUCCESS;
}输出如下:
2
Abort
分析工具都使用类似下面的工作流程来检测非返回函数
(13) 算法 [Dyninst, Ghidra, Angr, Bap, Radare2]:首先它们收集已知不返回的库函数或系统调用组。 其次,从这组函数中,进一步寻找其他函数
(14) 算法 [Dyninst, Bap, Radare2]:angr、radare2、dyninst扫描每个函数,如果没有找到 ret 指令,它们认为该函数是No-return函数
但是,当遇到对返回状态未知的子函数的调用时,它们采取了不同的解决方案
- angr简单的跳过处理
- radare2和angr类似,但是如果后面分析后确定返回状态,那么会递归的进行更新
- Dyninst 采用深度优先的方法,首先处理后继函数,只有在确定子函数的状态后,dyninst才会继续处理原始调用。
评估发现,radare2 和 dyninst 的策略是等效的。 两者的策略都产生了近乎完美的准确性
(14) 算法 [Dyninst, Bap, Radare2]:Ghidra也与上面类似,但是只扫描两遍,不是递归更新
(14) 算法 [Dyninst, Bap, Radare2]:如果函数中的所有路径都以对No-return函数的调用结束,则 BAP 认为该函数是No-return函数。 为了处理对状态未知的子函数的调用,它采用与 radare2类似的递归更新策略。
SUMMARY
分析工具使用了很多有效的策略来检测不返回函数,确保更高的正确性
CFG重建技术剖析#
在这部分,主要评测 5 个目标:(1)基本块之间的过程内边; (2) 直接调用的调用图; (3) 间接跳转和间接调用; (4) 尾调用; (5) No-return函数
综合性结论#
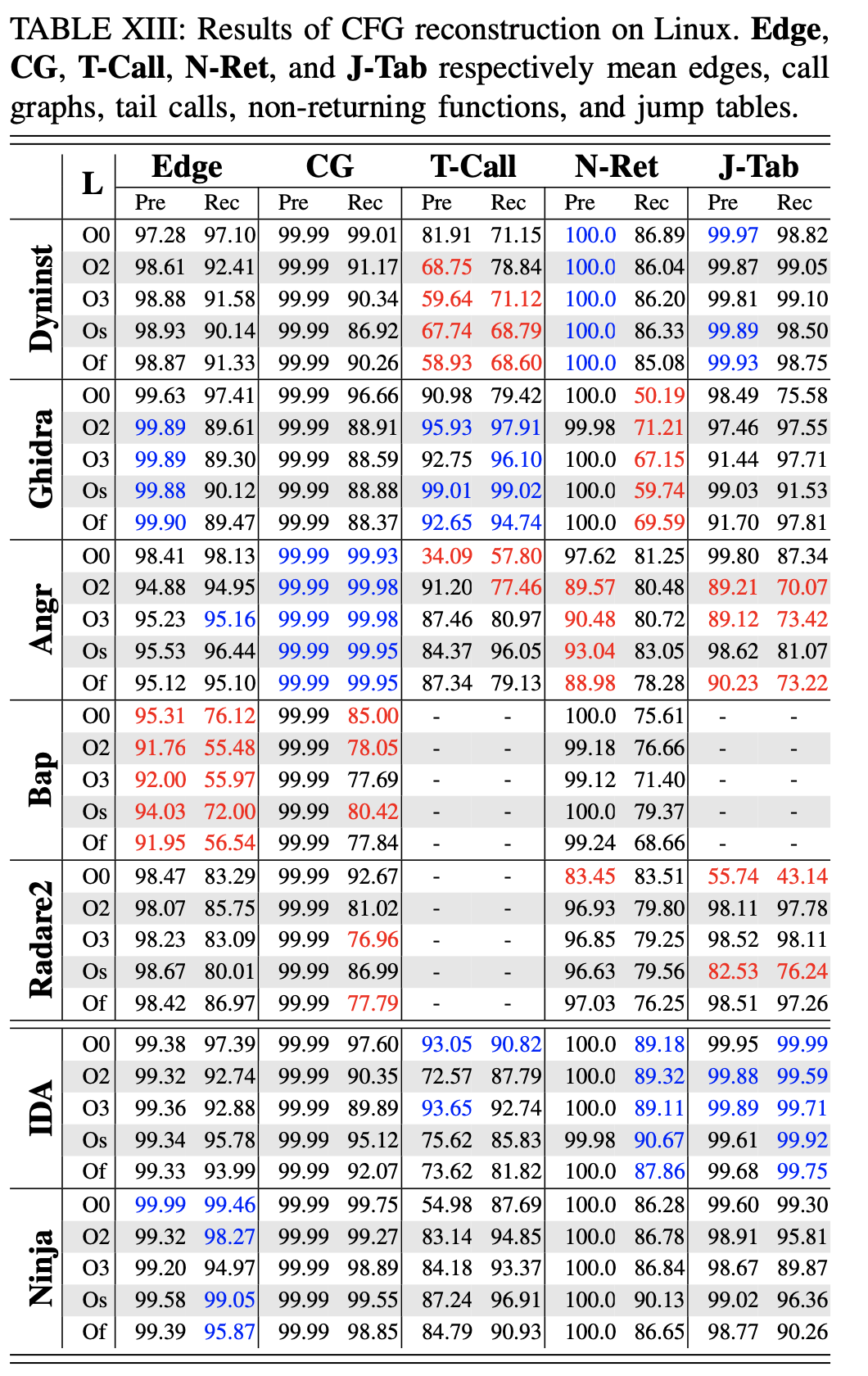
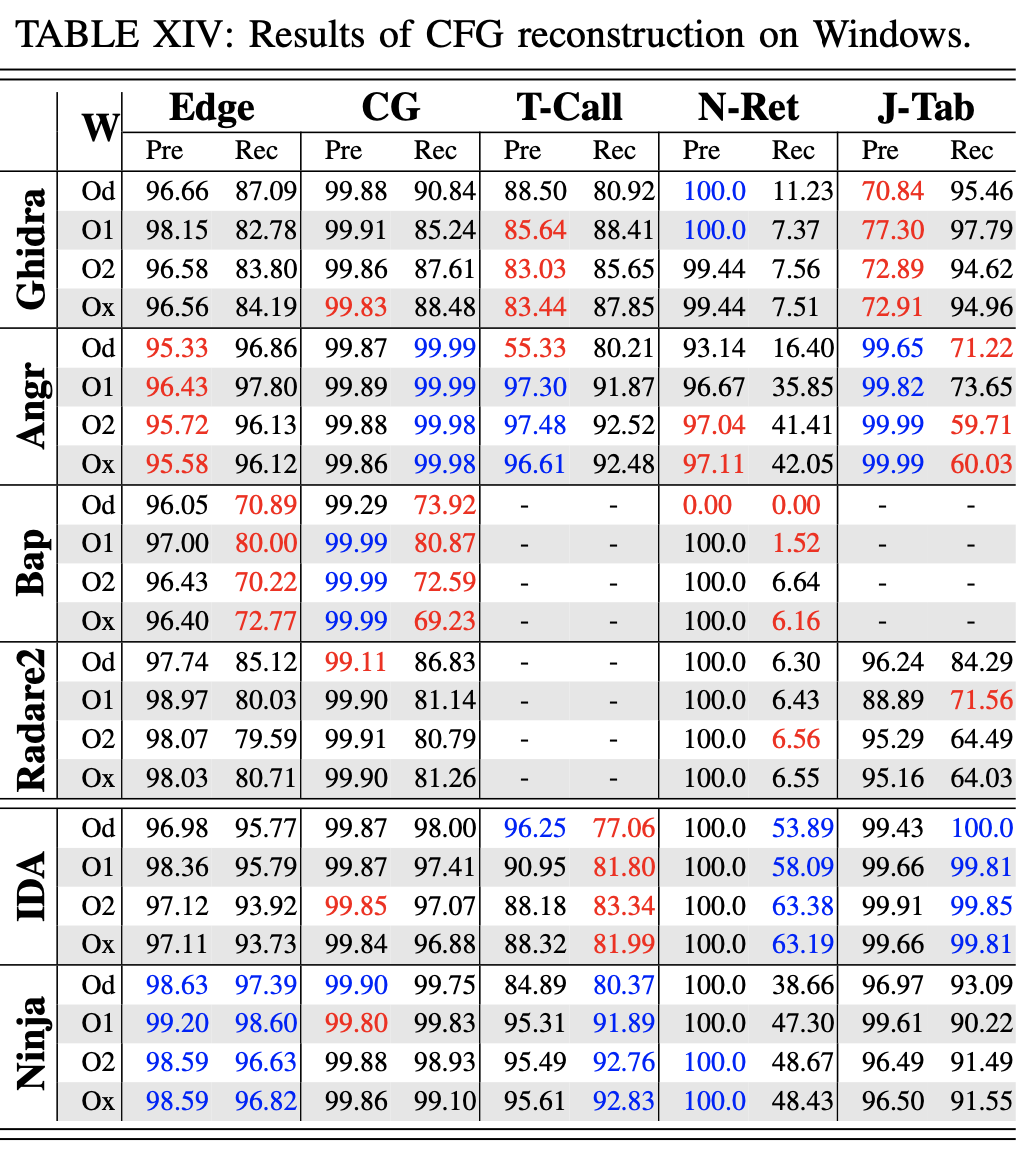
第一,这些工具可以高精度地恢复大部分边。 DYNINST、GHIDRA 和 ANGR 以高于 95% 的准确率找到了超过 90% 的边。 此外,边的恢复与指令的恢复高度相关:两个任务中的精度和召回率是一致的, 调用图的结果也类似。ß
第二,这些工具对跳转表的处理能力不同。 平均而言,GHIDRA 和 DYNINST 可以解析超过 93% 的跳转表,准确度约为 90%。 RADARE2 和 ANGR 具有相似的覆盖率(大约 75%),而 ANGR 的准确度要高得多(96.27% 对 90%)。 与开源工具相比,商业工具具有更高的覆盖率(96.5% vs. 84.8%)和准确性(99% vs. 92.96%)。
除了跳转表,还有另外两种类型的间接跳转:手动编写的汇编代码(336 例)和间接尾调用(35,087 例)。 对于第一种类型,GHIDRA 通过分析不断传播结果,找到了其中的96 个例。 BINARY NINJA 找到了其中的120 例,但对跳转目标的解析不正确。
第三,ANGR、GHIDRA、IDA PRO、BINARY NINJA对间接调用的支持都十分有限
第四,现有工具在检测尾调用方面并不完美,可以观察到许多工具(ANGR、GHIDRA、BINARY NINJA)在禁用优化的情况下具有最低的准确率。 这是因为在较低的优化级别会生成很较少的尾调用,并且一些误报可能会导致准确率降低。
最后,工具可以以非常高的准确率(对许多工具而言接近 100%)检测No-return函数。 但是,它们的覆盖范围有限,尤其是在 Windows 二进制文件上。 根据分析,在Windows二进制文件上覆盖率低的根本原因是非返回库函数的集合不完整。
启发式的使用#
- RADARE2、GHIDRA 和 DYNINST 使用模式来检测跳转表,能够所有跳转表的 85.53%、98.01% 和 99.56%
- DYNINST 和 ANGR 限制了 VSA 中的切片范围,在许多跳转表中缺少索引。通过将切片的范围扩大到 DYNINST 中的 500 个赋值和 ANGR 中的 10 个基本块,这两个工具在 2.1% 和 19.8% 的跳转表中找到了索引。
- GHIDRA 和 RADARE2 丢弃索引超过 1,024 和 512 的跳转表,分别漏报了 51 和 2,435 个跳转表。
- 为了检测尾部调用,RADARE2 依赖于jmp指令与其目标之间的距离。因此很难选择一个合适的阈值:在基准二进制文件中,常规跳转(最小值:0;最大值:0xb5867)和尾调用(最小值:0;最大值:0xb507c5)的距离在很大程度上是重叠的。
- GHIDRA 使用尾调用及其目标跨越多个函数的启发式方法。这种启发式方法通常用于捕获尾调用,产生 91.29% 的高覆盖率。但是,它无法识别非连续函数之间的规则跳跃,从而产生超过 70K 的误报。 Angr和Dyninst 使用基于控制流和堆栈高度的启发式方法,检测到了4.24% 和 6.99% 以上的尾调用
错误引入#

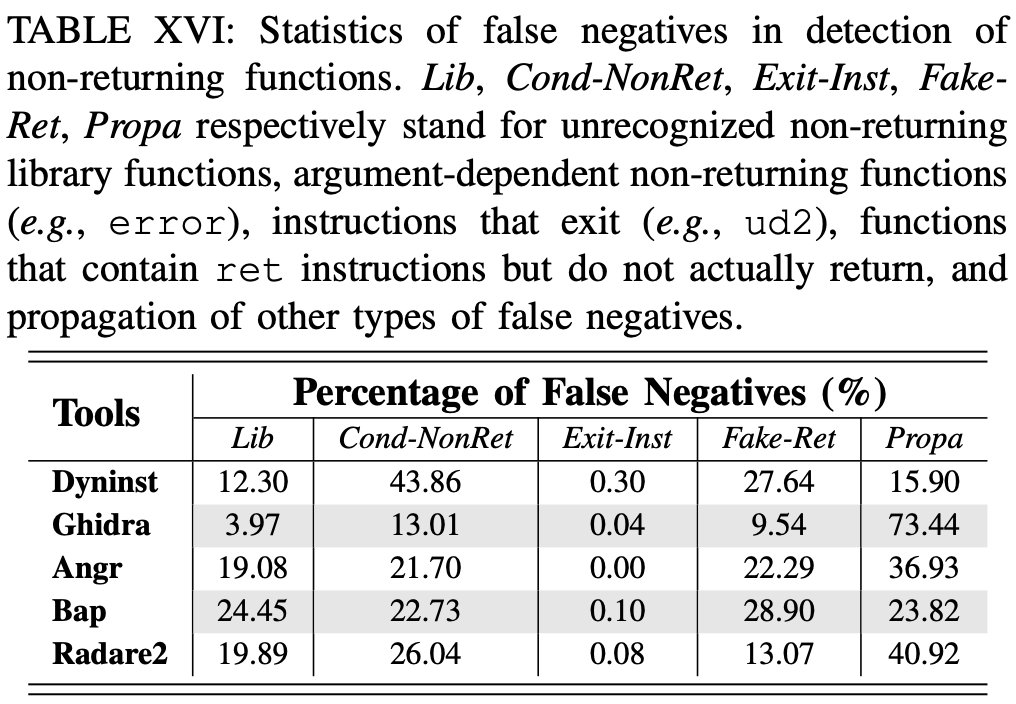
控制流边的误报主要是由未恢复的指令引起的
对于调用图,误报和漏报通常是反汇编错误的副作用。
与跳转表相关的错误是特定于二进制和工具的
- RADARE2、GHIDRA 和 DYNINST 依靠模式来检测跳转表,导致其误报率分别为 64.1%、31.4% 和 37.72%。此外,RADARE2 会产生 35.9% 的漏报,因为它丢弃了超过 512 个条目的跳转表;
- GHIDRA 产生了 62.63%、5.50% 和 0.47% 的漏报,分别是因为它没有考虑 VSA 分析中的sub指令,没有对索引进行正确限制,并丢弃了超过 1024 个条目的跳转表;
- Angr 的漏报是由于没有 VSA 分析结果(67.86%)、错误的 VSA 结果(14.29%)以及没有处理 sbb 指令(17.86%)
- DYNINST 的漏报是由于其限制切片范围 (2.1%) 和没有处理 get_pc_thunk (60.18%) 造成的
在检测尾调用时,存在大量的漏报和少量误报,原因如下:
- 漏报的原因分别有:
- 排除条件跳转
- 相邻函数之间缺少边界
- 排除条件跳转和无条件跳转都达到的目标
- 堆栈高度计算不正确
- 无法识别的函数
- jmp前没有堆栈调整模式
- 误报的原因有
- 错误的函数入口识别
- 非连续函数
- 指令遵循添加 esp/rsp,CONST 的格式但不拆除堆栈
- Jmp前的堆栈高度不变我们还注意到 ANGR 的误报包含一组条件跳转
检测No-return函数
- 具有 ret 指令但不返回的函数(例如,Glibc 中的 _Unwind_Resume)。此类函数更改堆栈来使用自己准备的返回地址,从而避免返回到caller,这回产生漏报
- DYNINST 没有误报
- 由于未处理的跳转表 (23.40%)、错误的函数入口点识别 (4.26%) 以及其他误报的传播 (72.34%),RADARE2 会产生误报。
- 由于未处理的跳转表/尾调用 (29.73%)、错误的函数边界 (54.05%) 和其他误报的传播 (16.22%),ANGR 会产生误报。
- 由于启发式 29,GHIDRA 会产生误报
- BAP 的误报是因为实现问题。
总结性发现#
本文的主要发现总结如下:
- 二进制中复杂的结构很常见,启发式方法对于处理复杂结构是必不可少的
- 启发式本质上引入了对覆盖率-准确性的权衡。启发式显著的增加了覆盖率,但同时会导致新的错误
- 工具之间相辅相成,现有工具使用的启发式和算法虽然有所重叠但也有许多差异,这体现了工具的不同优势,表明工具的选择应该是针对特定需求的
- 未来的改进需要更广泛、更深入的评估,现在的社区中国可能没有充分评估现有工具,导致我们对工具的局限性不够了解

