The Art, Science, and Engineering of Fuzzing(TSE 2019)
Abstract#
Fuzzing三大优点:部署简单、门槛低、已有的大量经验证明了它的有效性。
前人研究已经很多了,本文主要是做了一个系统的梳理blabla套话,目的是系统地探索模型模糊器各个阶段的设计决策,使我们的fuzzing设计更加行之有效。
Introduction#
对于hacker来说,fuzzing可以用来进行渗透测试和编写exp,而白帽则想利用fuzzing在被hacker攻击前找到漏洞所在。
此前已经有很多成功的研究和经典的fuzzing案例了,但不行的是,fuzzing好像遇到了瓶颈。后面的话没用了,大意就是不同论文表意不一致云云等原因搞的fuzzing领域的研究有点乱了。
所以,本文需要对前面的所有fuzzing研究进行提炼和升华。
章节安排:
第2节统一fuzzing术语和核心fuzzing框架,3-7节讲fuzzing每个阶段,调查相关文献,解释设计选择,讨论重要的权衡,并强调许多了不起的工程努力,有助于使现代fuzzing有效地完成其任务。
Systemization, Taxonomy, and Test Programs#
fuzzing & fuzzing testing#
Fuzzing:对可能的输入进行采样,得到对应的输出,类似于x->f(x)
Fuzzi testing: 目标是为了寻找bug和漏洞的fuzzing
Fuzzer:进行fuzz testing的程序
Fuzz Campaign:有一定安全策略的运行一个fuzzer
Bug Oracle:待检测的样本
Fuzz Configuration:fuzz的算法和策略,例如种子如何生成等
Paper Selection Criteria#
选了哪些会议的文章云云
Fuzz Testing Algorithm#

模糊测试的算法目的是:在有限的时间,一定的约束条件下找到有限的bugs
算法可以分为两个部分:Preprocess部分和 n轮的循环,循环包含五个部分(但在实际中有的可以不要):schedule、inputgen、inputeval、confupdate、continue,从名字上可以很显然的看出来都是在做什么。一次循环在本文中称为fuzz iteration,简单理解就相当于编译里面的一个pass吧。一次inputeval称为fuzz run。
- $\text{PREPROCESS}(\mathbb{C}) \rightarrow \mathbb{C}$ :根据用户的fuzzing configuration 进行一些可能的修改和获取一些fuzz中需要信息,比如插装,样本运行时间等
- $\text { SCHEDULE (} \mathbb{C}, \left.t_{\text {elapsed }}, t_{\text {limit }}\right) \rightarrow \text { conf }$ :根据当前时间和截止时间从当前的fuzzing configure里选取一个待测configure
- $\text { INPUTGEN (conf) } \rightarrow \text { tcs }$ :根据configure生成待测用例
- $\text { Inpureval (conf, }\left. \text { tcs, } O_{\text {bug }}\right) \rightarrow \mathbb{B}^{\prime} , execinfos$ : 以生成用例和configure,并嵌入bug oracle(检查是否为bug)输入,得到bug和执行信息
- $\text { CONFUPDATE (} \mathbb{C}, conf, execinfos) \rightarrow \mathbb{C}$ :更新策略
- $\text { CONTINUE }(\mathbb{C}) \rightarrow{\text { True, False }}$ :判断是否退出
Taxonomy of Fuzzers#
黑盒、白盒、灰盒
Fuzzer Genealogy and Overview#
不得不说汇总的真详细,直接po图了,各个研究的时间线,黑白灰,以及侧重方向一览无余
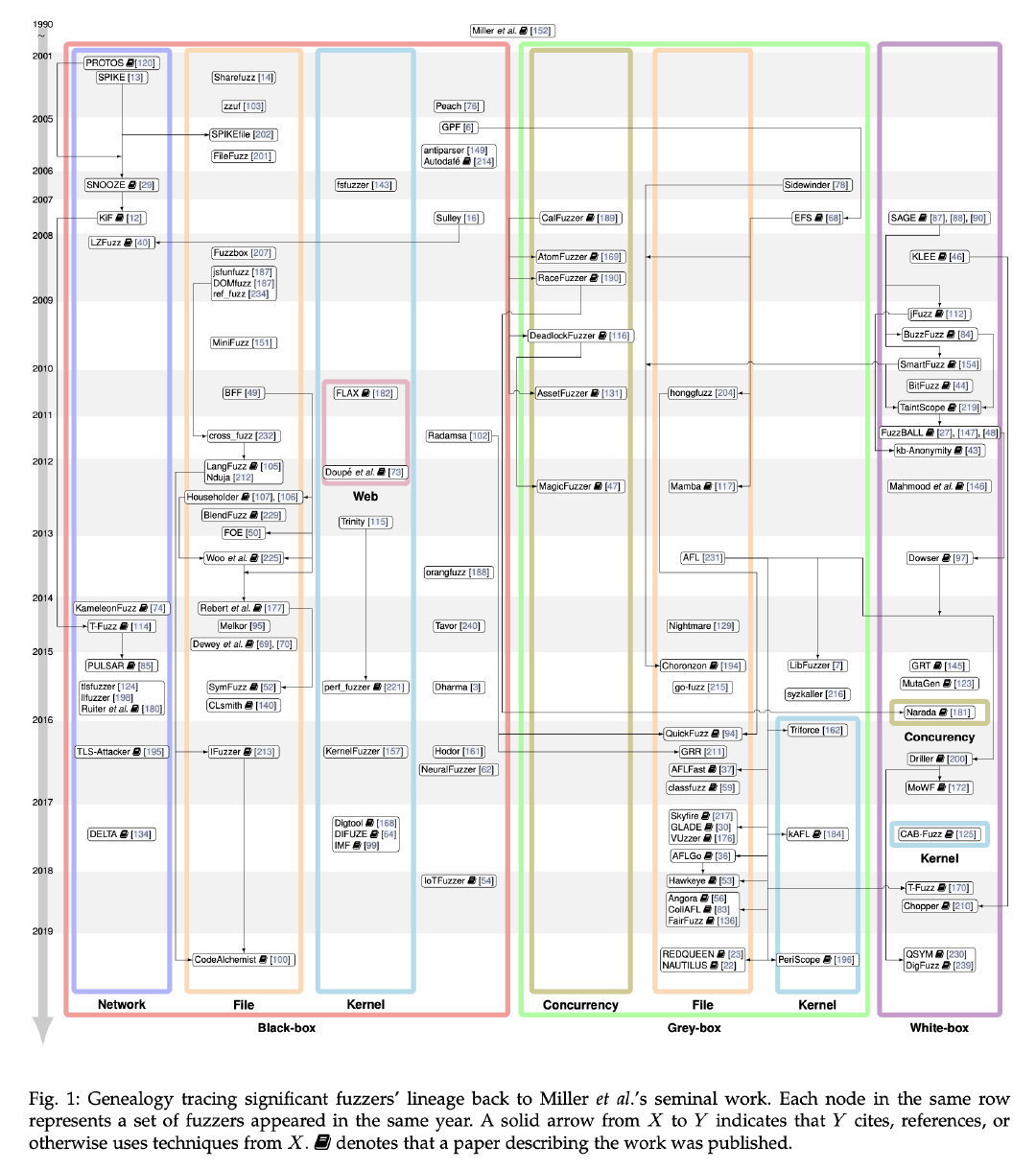
以及一个整理好的表
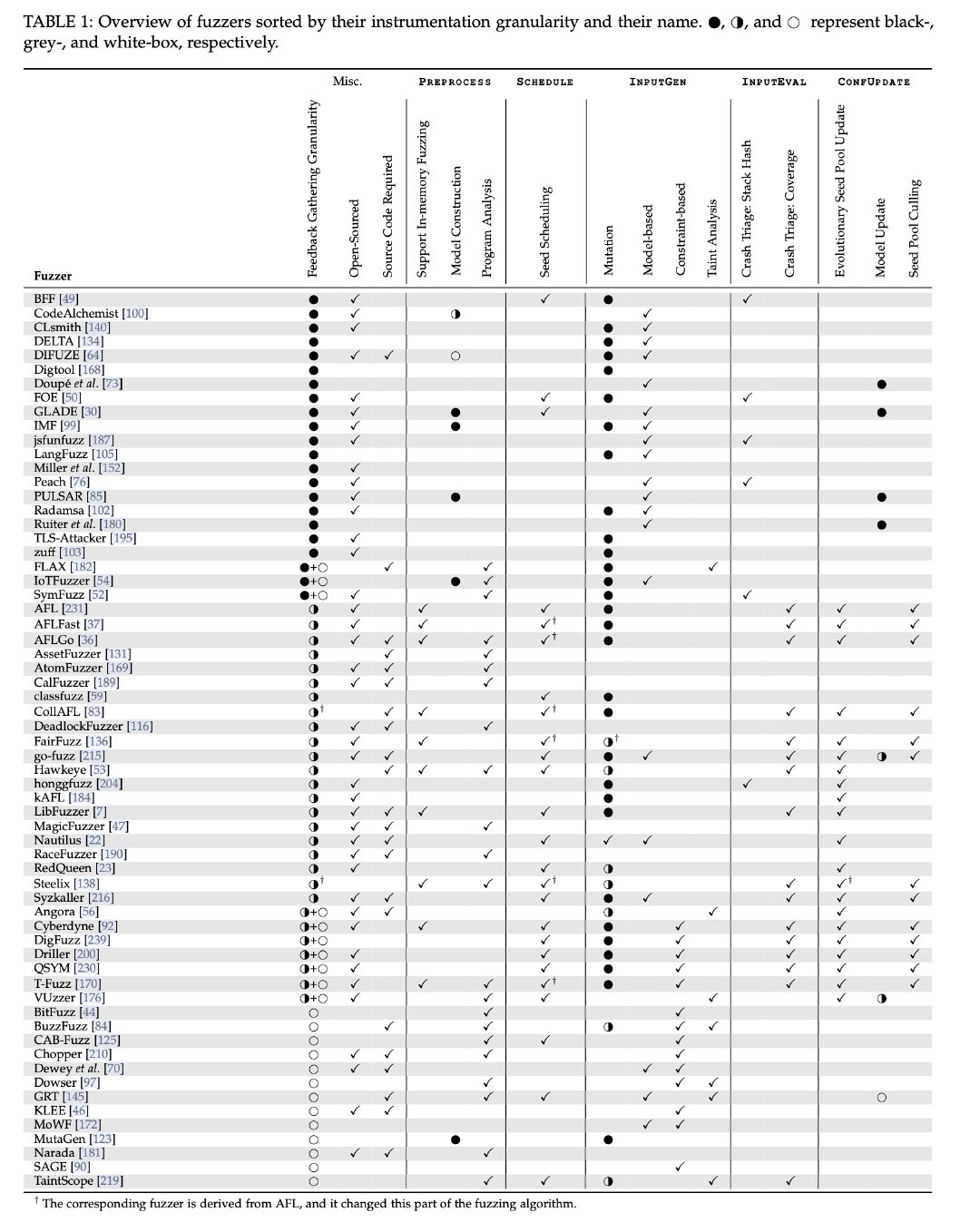
PreProcess#
Instrumentation#
通过插桩来获取在fuzz过程中的有用信息,可以是静态的插桩,也可以是动态的插桩
静态插桩需要的开销要小,但是需要找同版本的依赖库编译,除了源代码级别的静态插桩,也有二进制级别的静态插桩
动态插桩需要的开销要大,不过好处是更容易检测动态链接库,工具有:DynInst , DynamoRIO , Pin , Valgrind, and QEMU.
有的fuzzer可以静态插桩也可以动态插桩
- Execution Feedback:
- 路径覆盖:AFL及其衍生、CollAFL
- 结点覆盖:LibFuzzer、Syzkaller
- 可选:Honggfuzz
- In-Memory Fuzzing:对于一些应用,例如有GUI的程序,初始化绘制GUI什么会浪费时间,这个时候可以dump下初始化后的内存空间来节约时间。有的fuzzer在内存中对一个函数反复fuzzing,称为API fuzzing。缺点:1.不好重建bug产生时的上下文进行复现。2.对于跨函数调用的fuzz可能会出问题。
- Thread Scheduling:条件竞争很难触发,因为它们依赖于不确定的行为,这种行为可能很少发生。但是,通过显式地控制线程的调度方式,插桩也可以用来触发不同的非确定性程序行为已有的研究表明,即使随机调度线程也可以有效地发现竞争条件错误。
Seed Selection#
有的情况下fuzzing的取值域会很广,例如MP3文件等。
因此如何选择最小的初始化种子集合称为种子选择问题,目的是:找到最小的初始种子集合,使得在fuzzing过程中覆盖率最大化。也就是使得fuzzing的效率更高。
例如我们有种子s1,它能覆盖到{10,20},以及s2->{20,30},那么如果这个时候种子s3->{10,20,30},则显然以s3作为初始种子更加高效。
Seed Trimming#
较小的种子集合可能会消耗较少的内存并引发更高的吞吐量,所以一些fuzzers在fuzz之前减小种子集合的大小,这便是种子集合的修剪。
一般发生在PREPROCESS或者CONFUPDATE之中
Preparing a Driver Application#
对于一些没法直接fuzzing的情况,可能需要自己写一个driver程序。
SCHEDULING#
调度是只选择一个fuzz configuration,然后进入下一轮的fuzz。对于简单的fuzzer,例如zzuf,则没有这个步骤。已有的研究中,ADLFast,BFF等的亮点就在于他们使用的调度策略。
本节只讨论黑盒和灰盒 fuzzing中的调度策略。
The Fuzz Configuration Scheduling (FCS) Problem#
调度的目标:
- 分析当前configure信息
- 找到可能有最好结果的输入:bugs最多或者覆盖面最大
- …
还有一些算法1中的解释,很明白
Black-box FCS Algorithms#
对于黑盒fuzzing来说,能够用于FCS的只有:已有的crashes和bugs信息+执行时间
举例
- HouseHolder、Foote提出成功率指标:#bugs / #runs
- MAB 算法:faster to fuzz allows a fuzzer to either collect more unique bugs with it, or decrease the upperbound on its future success probability more rapidly.
Grey-box FCS Algorithms#
灰盒fuzzing能获取的信息比黑盒更多,例如覆盖率等信息
AFL提出EA算法,EA算法维护了一系列的configuration,从中间选取fit的configurations用来生成待测用例
疑问三连:
- what makes a configuration fit?
- how configurations are selected
- how a selected configu- ration is used.
大部分fuzzers都会考虑控制流关系。
AFL的策略是选取最快最小的输入,称为fit(favorite)的
AFLfast优化了AFL,快7倍,发现了3个AFL没发现的bug
选择路径频率最小的来探索稀有路径
基于优先级来选择configuration,而不是循环选择
使用power schedul
AFLGo进一步优化了优先级策略
INPUT GENERATION#
有的fuzzer通过在原有seed上突变来产生下一次的输入,而有的基于model产生下一次的输入
Model-based (Generation-based) Fuzzers#
predefined model 预定义模型:1.在使用前由user定义模型;2. 模型由fuzzer通过预定义的语法等来自动构建
Inferred Model 推断模型:发生在PREPROCESS和CONFUPDATE阶段,通过数据驱动、状态机等实现推断
Encoder Model:常用于有固定格式的文件的fuzzer
Model-Less (Mutation-based)Fuzzers#
这个很常见
- 比特位翻转
- 算数变异
- 基于块的变异
- 基于字典的变异
White-box Fuzzers#
- 动态符号执行
- 启发式fuzzing
- 输入变异
INPUT EVALUATION#
是对输入进行执行以及分析的过程
Bug Oracles#
用于判断是否有crash 或者有bug的policy,分类举例如下
Memory and Type Safety:Address Sanitizer、SoftBounf/CETS、CFI
Undefined Behaviors:Memory Sanitizer 、Undefined Behavior Sanitizer、Thread Sanitizer
Input Validation:KameleonFuzz、μ4SQLi
Semantic Difference:black-box differential fuzz
Execution Optimizations#
由于需要频繁运行程序,所以需要进行执行优化。例如函数级别的fuzz、通过fork已有的进程来免去加载时间等等
Triage#
分类是分析和报告导致违反策略的测试用例的过程。分类可以分为三个步骤:重复数据消除、优先级划分和测试用例最小化。
- 重复数据消除方法:Stack Backtrace Hashing、Coverage-based Deduplication、Semantics-aware Deduplication
- Prioritization and Exploitability:著名的有WinDbg的自动检测能够被利用!expoitable
- Test case minimization:例如BFF、AFL等fuzzer使用的策略
CONFIGURATION UPDATING#
黑盒、白盒、灰盒fuzzing在这一个步骤上区别很大
- Evolutionary Algorithm:维护seed pool,使其尽可能到达更多的路径
- Maintaining a Minset:最小化测试用例集合,最大化覆盖率
个人感觉#
整体上写了很多,并且分类也十分细致,抽取出了一个fuzzer的框架,但东西太多,点到为止。
看完其他的fuzzing paper再回来看这篇论文收获会更大。

